Analítica de
Datos con R
Visualización de Datos
Tendencias Futuras
Ética y privacidad en la era de los big data
Ética y privacidad en la era de los big data. Desafíos y oportunidades.
La era del Big Data ha traído consigo una revolución en la forma en que recopilamos, almacenamos y analizamos información. Sin embargo, esta revolución también plantea importantes desafíos éticos y de privacidad. En esta unidad, exploraremos los principales desafíos éticos relacionados con el Big Data, así como las oportunidades que surgen para proteger la privacidad y garantizar un uso responsable de los datos.
Conceptos Clave
- Big Data: Grandes volúmenes de datos estructurados y no estructurados que se generan a una velocidad sin precedentes.
- Privacidad: El derecho de las personas a controlar su información personal.
- Ética: Un conjunto de principios morales que guían la conducta humana.
Desafíos Éticos en la Era del Big Data
- Privacidad:Recopilación masiva de datos personales sin consentimiento.
- Uso indebido de datos personales para fines comerciales o de vigilancia.
- Dificultad para mantener la privacidad en un mundo cada vez más conectado.
- Sesgos en los datos:Perpetuación de estereotipos y discriminación a través de algoritmos sesgados.
- Toma de decisiones injustas basadas en datos incompletos o sesgados.
- Seguridad de los datos:Riesgo de filtraciones de datos y ciberataques.
- Vulnerabilidad de los sistemas de almacenamiento de datos.
- Transparencia:Falta de transparencia en los algoritmos y modelos utilizados para analizar los datos.
- Dificultad para comprender y explicar las decisiones basadas en datos.
Oportunidades para la Ética en el Big Data
- Legislación:Desarrollo de marcos legales robustos para proteger la privacidad y garantizar el uso responsable de los datos.
- Ejemplos: RGPD (Reglamento General de Protección de Datos), CCPA (California Consumer Privacy Act).
- Tecnología:Desarrollo de tecnologías de anonimización y encriptación para proteger los datos personales.
- Creación de herramientas para detectar y mitigar sesgos en los algoritmos.
- Educación:Fomentar la conciencia sobre los desafíos éticos del Big Data entre los profesionales de la tecnología y el público en general.
- Colaboración:Fomentar la colaboración entre investigadores, empresas, gobiernos y la sociedad civil para desarrollar soluciones éticas.
Principios Éticos para el Uso del Big Data
- Transparencia: Ser transparente sobre cómo se recopilan, almacenan y utilizan los datos.
- Justicia: Garantizar que los algoritmos y modelos no perpetúen sesgos o discriminaciones.
- Responsabilidad: Asumir la responsabilidad por las consecuencias de las decisiones basadas en datos.
- Privacidad: Respetar el derecho de las personas a controlar su información personal.
- Seguridad: Proteger los datos de accesos no autorizados y filtraciones.
Casos de Uso y Ejemplos
- Salud: Uso de datos genómicos para personalizar tratamientos, pero con el riesgo de discriminación.
- Marketing: Segmentación de clientes basada en datos personales, pero con el riesgo de violaciones de la privacidad.
- Gobierno: Uso de datos para mejorar la toma de decisiones políticas, pero con el riesgo de vigilancia masiva.
Realidad virtual y aumentada en la visualización
Realidad virtual y aumentada en la visualización. Nuevas formas de interactuar con los datos.
La realidad virtual (RV) y la realidad aumentada (RA) están revolucionando la forma en que interactuamos con el mundo digital. Estas tecnologías inmersivas están encontrando aplicaciones cada vez más sofisticadas en el campo de la visualización de datos, ofreciendo nuevas formas de explorar y comprender información compleja. En esta unidad, exploraremos cómo la RV y la RA están transformando la manera en que visualizamos y analizamos datos.
Conceptos Clave
- Realidad Virtual (RV): Un entorno simulado generado por computadora en el que el usuario puede interactuar.
- Realidad Aumentada (RA): La superposición de elementos digitales sobre el mundo real, creando una experiencia mixta.
- Inmersión: La sensación de estar completamente inmerso en un entorno virtual o aumentado.
- Interacción: La capacidad de manipular y explorar los datos de forma intuitiva y natural.
Aplicaciones de la RV y RA en la Visualización de Datos
- Exploración de datos en 3D: Visualización de datos espaciales, como edificios, ciudades o sistemas biológicos, en entornos 3D inmersivos.
- Análisis de grandes conjuntos de datos: Exploración de datos multidimensionales a través de interfaces intuitivas y personalizables.
- Simulaciones y modelado: Creación de simulaciones interactivas para analizar el comportamiento de sistemas complejos.
- Capacitación y entrenamiento: Desarrollo de experiencias de aprendizaje inmersivas para enseñar conceptos complejos.
- Colaboración en tiempo real: Facilitar la colaboración entre equipos distribuidos en entornos virtuales compartidos.
Beneficios de la RV y RA en la Visualización
- Mayor inmersión: La RV y la RA permiten a los usuarios sumergirse completamente en los datos, facilitando la comprensión y el análisis.
- Interacción intuitiva: Gestos, movimientos o comandos de voz permiten una interacción más natural con los datos.
- Visualización de datos complejos: La RV y la RA pueden manejar grandes volúmenes de datos y visualizaciones multidimensionales de manera efectiva.
- Mejora de la toma de decisiones: Al proporcionar una comprensión más profunda de los datos, estas tecnologías pueden mejorar la calidad de las decisiones.
Desafíos y Limitaciones
- Costo: El hardware y el software necesarios para la RV y la RA pueden ser costosos.
- Ergonomía: El uso prolongado de dispositivos de RV puede causar fatiga visual y otros problemas de salud.
- Desarrollo: La creación de experiencias inmersivas requiere habilidades de desarrollo especializadas.
- Disponibilidad de contenido: La cantidad de contenido de RV y RA para la visualización de datos aún es limitada.
Tendencias Futuras
- Integración con otras tecnologías: Combinación de la RV y la RA con inteligencia artificial, aprendizaje automático y big data.
- Aplicaciones en diferentes industrias: Expansión de las aplicaciones de la RV y la RA a nuevos sectores, como la medicina, la ingeniería y la educación.
- Dispositivos más accesibles: Desarrollo de dispositivos más asequibles y fáciles de usar.
Ejemplos de Aplicaciones
- Arquitectura: Diseño y visualización de edificios en 3D.
- Medicina: Visualización de datos médicos en 3D para diagnóstico y planificación de tratamientos.
- Ingeniería: Simulación de procesos industriales y diseño de productos.
- Educación: Creación de experiencias de aprendizaje inmersivas en ciencias, matemáticas y otras disciplinas.
Inteligencia artificial y visualización de datos
Inteligencia artificial y visualización de datos. Aprendizaje automático para generar visualizaciones.
La intersección de la inteligencia artificial (IA) y la visualización de datos está dando lugar a nuevas y emocionantes posibilidades. El aprendizaje automático, una rama de la IA, está transformando la forma en que creamos y consumimos visualizaciones. En esta unidad, exploraremos cómo la IA puede automatizar la generación de visualizaciones, permitiendo a los analistas de datos concentrarse en la interpretación y la toma de decisiones.
Conceptos Clave
- Generación automática de visualizaciones: El uso de algoritmos de aprendizaje automático para seleccionar el tipo de gráfico más adecuado, ajustar los parámetros visuales y generar visualizaciones de alta calidad de forma automática.
- Aprendizaje profundo: Un subconjunto del aprendizaje automático que utiliza redes neuronales artificiales para aprender representaciones jerárquicas de datos complejos.
- Visión por computadora: El campo de la IA que se enfoca en permitir a las computadoras interpretar y comprender el contenido visual de imágenes y videos.
Cómo Funciona la Generación Automática de Visualizaciones
- Análisis de los datos: El algoritmo de aprendizaje automático analiza los datos para identificar patrones, relaciones y distribuciones.
- Selección del tipo de gráfico: Basado en las características de los datos, el algoritmo selecciona el tipo de gráfico más adecuado (barras, líneas, dispersión, etc.).
- Optimización de los parámetros visuales: El algoritmo ajusta los parámetros visuales, como colores, tamaños y etiquetas, para maximizar la claridad y la efectividad de la visualización.
- Generación de la visualización: El algoritmo crea la visualización final, que puede ser estática o interactiva.
Beneficios de la Generación Automática de Visualizaciones
- Ahorro de tiempo: Automatiza tareas repetitivas y consume mucho tiempo, permitiendo a los analistas centrarse en tareas de mayor valor.
- Mayor precisión: Los algoritmos de aprendizaje automático pueden identificar patrones que los humanos pueden pasar por alto.
- Escalabilidad: Permite generar rápidamente una gran cantidad de visualizaciones para explorar diferentes perspectivas de los datos.
- Accesibilidad: Facilita la creación de visualizaciones para personas sin conocimientos técnicos en visualización de datos.
Desafíos y Limitaciones
- Interpretabilidad: Los modelos de aprendizaje automático pueden ser difíciles de interpretar, lo que dificulta entender cómo se tomaron las decisiones.
- Sesgos: Los algoritmos pueden perpetuar los sesgos presentes en los datos de entrenamiento.
- Creatividad: La generación automática puede limitar la creatividad y la capacidad de los humanos para contar historias con los datos.
Aplicaciones Prácticas
- Exploración de datos: Generar rápidamente una variedad de visualizaciones para identificar patrones y tendencias.
- Creación de dashboards: Automatizar la actualización de dashboards con nuevas visualizaciones.
- Visualización de datos de alta dimensionalidad: Reducir la dimensionalidad de los datos y generar visualizaciones comprensibles.
Tendencias Futuras
- Visualizaciones interactivas generadas por IA: Visualizaciones que se adaptan en tiempo real a las interacciones del usuario.
- Generación de narrativas visuales: Creación de historias a partir de los datos, utilizando la visualización como medio de expresión.
- Visualización de datos en realidad virtual y aumentada: Experiencias inmersivas para explorar datos complejos.
Ejercicios Prácticos
Visualización de datos para la toma de decisiones
Visualización de datos para la toma de decisiones. Análisis exploratorio y predictivo.
La visualización de datos es una herramienta fundamental para transformar datos en conocimiento accionable. Al permitirnos explorar y entender grandes volúmenes de información de manera visual, podemos identificar patrones, tendencias y relaciones ocultas que son cruciales para la toma de decisiones informadas. En esta unidad, exploraremos cómo la visualización de datos puede apoyar tanto el análisis exploratorio como el predictivo.
Análisis Exploratorio de Datos (EDA) a través de la Visualización
- ¿Qué es el EDA? Un proceso iterativo de descubrimiento y visualización que describe los datos, encuentra patrones y detecta anomalías.
- Objetivos del EDA:Familiarizarse con los datos.
- Descubrir patrones, tendencias y relaciones.
- Detectar valores atípicos y errores.
- Sugerir hipótesis para pruebas posteriores.
- Técnicas de visualización para EDA:Histogramas: Para entender la distribución de una variable numérica.
- Box plots: Para comparar la distribución de múltiples variables.
- Gráficos de dispersión: Para visualizar la relación entre dos variables numéricas.
- Mapas de calor: Para identificar patrones espaciales.
- Matrices de correlación: Para evaluar la relación entre múltiples variables.
Visualización para el Análisis Predictivo
- ¿Qué es el análisis predictivo? El uso de modelos estadísticos y de machine learning para predecir futuros resultados.
- Rol de la visualización en el análisis predictivo:Exploración de datos: Identificar las variables más relevantes para el modelo.
- Evaluación del modelo: Visualizar la precisión del modelo y sus errores.
- Comunicación de resultados: Presentar los resultados de manera clara y concisa a un público no técnico.
- Técnicas de visualización:Curvas ROC: Para evaluar la capacidad de clasificación de un modelo.
- Importancia de las características: Para identificar las variables más importantes en un modelo.
- Árboles de decisión: Para visualizar las reglas de decisión de un modelo.
Casos de Uso en el Mundo Real
- Negocios:Análisis de ventas: Identificar productos populares, temporadas altas y bajas, y predecir futuras ventas.
- Análisis de clientes: Segmentar a los clientes, identificar sus necesidades y personalizar las campañas de marketing.
- Salud:Epidemiología: Visualizar la propagación de enfermedades y identificar factores de riesgo.
- Análisis genómico: Visualizar datos genómicos para identificar mutaciones y desarrollar tratamientos personalizados.
- Finanzas:Análisis de mercado: Identificar tendencias del mercado, evaluar el riesgo y optimizar las carteras de inversión.
- Detección de fraudes: Visualizar patrones de transacciones inusuales para detectar posibles fraudes.
Herramientas y Tecnologías
- Tableau: Ofrece una amplia gama de visualizaciones para EDA y análisis predictivo.
- Power BI: Integración con herramientas de Microsoft y capacidades de colaboración.
- Python (Pandas, Matplotlib, Seaborn): Gran flexibilidad y personalización para crear visualizaciones personalizadas.
- R (ggplot2): Popular entre la comunidad de estadística y data science.
Ejercicios Prácticos
- EDA de un conjunto de datos de ventas: Explorar los datos para identificar patrones y tendencias.
- Crear un modelo de predicción de churn de clientes: Visualizar la importancia de las características y evaluar la precisión del modelo.
- Analizar datos de sensores para detectar anomalías.
- Visualizar datos geográficos para identificar patrones espaciales.
Visualización de datos en tiempo real
Visualización de datos en tiempo real. Dashboards interactivos.
La visualización de datos en tiempo real ha revolucionado la forma en que las organizaciones toman decisiones. Los dashboards interactivos son herramientas poderosas que permiten monitorear y analizar datos a medida que se generan, proporcionando una visión en tiempo real de las operaciones y tendencias. En esta unidad, exploraremos los conceptos clave, las herramientas y las aplicaciones de los dashboards interactivos.
Conceptos Clave
- Datos en tiempo real: Datos que se recolectan y se actualizan continuamente.
- Dashboard: Una interfaz visual que presenta datos clave de manera concisa y fácil de entender.
- Interactividad: La capacidad de los usuarios de explorar los datos de diferentes maneras, filtrando, seleccionando y comparando.
Componentes de un Dashboard Interactivo
- Fuentes de datos: Bases de datos, API, sensores, hojas de cálculo.
- Visualizaciones: Gráficos, tablas, mapas, indicadores clave de rendimiento (KPIs).
- Filtros: Permiten a los usuarios segmentar los datos y enfocarse en áreas específicas.
- Slicers: Controladores que permiten seleccionar diferentes valores de una dimensión.
- Actualizaciones en tiempo real: Mecanismos para actualizar los datos de forma automática.
Beneficios de los Dashboards Interactivos
- Toma de decisiones más rápida: Al proporcionar información actualizada, los dashboards permiten tomar decisiones oportunas.
- Mayor visibilidad: Los dashboards ofrecen una visión global de las operaciones y facilitan la identificación de tendencias y patrones.
- Colaboración mejorada: Los dashboards pueden ser compartidos con equipos multidisciplinarios, facilitando la colaboración.
- Mejora de la eficiencia: Los dashboards automatizan la recopilación y presentación de datos, liberando tiempo para el análisis.
Herramientas para Crear Dashboards Interactivos
- Tableau: Ofrece una amplia gama de visualizaciones y capacidades de interacción.
- Power BI: Integración profunda con el ecosistema de Microsoft y excelentes capacidades de colaboración.
- Google Data Studio: Opción gratuita y fácil de usar para crear dashboards a partir de diferentes fuentes de datos.
- Python (Plotly, Dash): Gran flexibilidad y personalización para crear dashboards personalizados.
Casos de Uso
- Negocios: Monitoreo de ventas, análisis de marketing, seguimiento de inventarios.
- Operaciones: Monitoreo de la producción, gestión de la cadena de suministro, mantenimiento predictivo.
- Salud: Seguimiento de pacientes, análisis de datos clínicos, gestión de recursos hospitalarios.
- Finanzas: Análisis de mercado, gestión de riesgos, seguimiento de inversiones.
Desafíos y Consideraciones
- Calidad de los datos: La calidad de los datos es fundamental para la efectividad de un dashboard.
- Diseño: Un diseño claro y conciso es esencial para garantizar que los usuarios puedan interpretar fácilmente la información.
- Performance: Los dashboards deben ser rápidos y responsivos, especialmente cuando se trata de grandes volúmenes de datos.
- Seguridad: Es necesario proteger los datos confidenciales y garantizar el acceso autorizado a los dashboards.
Proyectos Prácticos
- Crear un dashboard para monitorear el tráfico web de un sitio web.
- Desarrollar un dashboard para visualizar los datos de sensores de una planta de producción.
- Construir un dashboard interactivo para analizar las tendencias del mercado de criptomonedas.
Visualización de datos espaciales
Visualización de datos espaciales. Mapas y geovisualización.
La visualización de datos espaciales, o geovisualización, es una rama de la visualización de información que se enfoca en representar datos geográficos en mapas y otros formatos visuales. Esta técnica es fundamental para entender patrones espaciales, relaciones geográficas y tendencias en una amplia variedad de campos, desde la geografía y la urbanística hasta el marketing y la epidemiología.
Fundamentos de la Geovisualización
- Datos geográficos: Tipos de datos geográficos (puntos, líneas, polígonos), sistemas de coordenadas y proyecciones cartográficas.
- Mapas temáticos: Cómo utilizar mapas para visualizar diferentes tipos de datos (densidad, distribución, cambios a lo largo del tiempo).
- Simbología: Selección de símbolos adecuados para representar diferentes tipos de datos.
- Color: El uso efectivo del color para resaltar patrones y diferencias.
Herramientas para la Geovisualización
- Software de Sistemas de Información Geográfica (SIG): ArcGIS, QGIS, MapInfo.
- Bibliotecas de programación: Python (GeoPandas, Folium), R (sf, leaflet).
- Herramientas en línea: Google Maps, Mapbox, Carto.
Tipos de Visualizaciones Espaciales
- Mapas de calor: Representan la densidad de los datos en un área determinada.
- Coropletas: Utilizan colores para mostrar variaciones en una variable numérica dentro de regiones.
- Mapas de puntos: Visualizan la ubicación de puntos individuales.
- Mapas de líneas: Representan conexiones entre diferentes ubicaciones.
- Mapas de flujo: Muestran el movimiento de personas, bienes o información entre diferentes lugares.
Aplicaciones de la Geovisualización
- Urbanismo: Planificación urbana, análisis del tráfico, identificación de zonas de riesgo.
- Medio ambiente: Monitoreo de la calidad del aire y del agua, análisis de patrones climáticos, seguimiento de la deforestación.
- Marketing: Análisis de la ubicación de los clientes, segmentación de mercados, evaluación de campañas publicitarias.
- Epidemiología: Seguimiento de la propagación de enfermedades, identificación de brotes, evaluación de la eficacia de las intervenciones.
Ejercicios Prácticos
- Crear un mapa de calor: Utilizar datos de densidad de población para crear un mapa de calor de una ciudad.
- Visualizar patrones de movilidad: Analizar datos de GPS para visualizar los patrones de movimiento de una población.
- Comparar múltiples variables: Crear un mapa que compare diferentes variables, como el ingreso per cápita y la tasa de desempleo.
- Crear una historia interactiva: Utilizar una herramienta de visualización interactiva para crear una historia que explore un tema geográfico.
Consideraciones Éticas
- Privacidad: Proteger la privacidad de los datos geográficos, especialmente cuando se trata de datos personales.
- Sesgos: Ser consciente de los posibles sesgos en los datos y en las visualizaciones.
- Interpretación: Evitar sacar conclusiones apresuradas y asegurarse de que la visualización se interpreta correctamente.
Proyectos Reales
- Análisis de la distribución de delitos en una ciudad.
- Evaluación del impacto de un desastre natural.
- Identificación de patrones de migración.
- Análisis de la distribución de especies en peligro de extinción.
Proyectos individuales o en equipo
Proyectos individuales o en equipo. Desarrollo de visualizaciones para resolver problemas del mundo real.
La visualización de datos no solo es una habilidad técnica, sino también una herramienta poderosa para resolver problemas reales y comunicar hallazgos de manera efectiva. En esta unidad, exploraremos cómo aplicar los conocimientos adquiridos en proyectos prácticos, tanto individuales como en equipo, para abordar desafíos del mundo real a través de la visualización de datos.
Fases de un Proyecto de Visualización
- Definición del problema:Identificar claramente la pregunta que se quiere responder con la visualización.
- Definir el público objetivo y sus necesidades.
- Recopilación y preparación de datos:Obtener los datos relevantes de fuentes confiables.
- Limpiar y transformar los datos para que sean adecuados para la visualización.
- Selección de la herramienta adecuada:Elegir la herramienta que mejor se adapte al tipo de datos y a la complejidad de la visualización.
- Diseño de la visualización:Seleccionar los tipos de gráficos más adecuados para comunicar los hallazgos.
- Considerar la estética y la facilidad de comprensión.
- Desarrollo de la visualización:Utilizar la herramienta seleccionada para crear la visualización.
- Iterar y refinar el diseño hasta obtener los resultados deseados.
- Comunicación de los resultados:Presentar la visualización de manera clara y concisa.
- Interpretar los hallazgos y responder a preguntas.
Proyectos Prácticos
- Proyectos individuales:Análisis de datos personales: Visualizar hábitos de gasto, patrones de sueño o actividad física.
- Exploración de datos públicos: Analizar datos de conjuntos de datos abiertos como los de gobiernos o organizaciones sin fines de lucro.
- Visualización de datos de redes sociales: Analizar la interacción en redes sociales, la influencia de los influencers o la evolución de las tendencias.
- Proyectos en equipo:Análisis de datos empresariales: Desarrollar dashboards para monitorear el desempeño de la empresa.
- Investigación académica: Visualizar resultados de experimentos o estudios.
- Proyectos de ciencia ciudadana: Participar en proyectos de ciencia ciudadana y contribuir con visualizaciones de datos.
Ejemplos de Problemas Reales a Resolver con Visualizaciones
- Salud: Visualizar la propagación de enfermedades, analizar los factores de riesgo y evaluar la eficacia de las intervenciones.
- Medio ambiente: Monitorear el cambio climático, analizar la calidad del aire y del agua, y visualizar patrones de consumo de energía.
- Economía: Analizar tendencias del mercado, predecir el comportamiento de los consumidores y evaluar el impacto de las políticas económicas.
- Deportes: Visualizar el desempeño de los atletas, analizar estadísticas de equipos y crear visualizaciones interactivas para los fanáticos.
Herramientas y Recursos
- Tableau Public: Plataforma gratuita para crear y compartir visualizaciones públicas.
- Google Data Studio: Herramienta gratuita para crear dashboards a partir de diferentes fuentes de datos.
- Kaggle: Plataforma para encontrar conjuntos de datos y participar en competiciones de ciencia de datos.
- GitHub: Repositorio de código abierto con numerosos ejemplos y proyectos de visualización de datos.
Consideraciones Éticas
- Privacidad: Asegurarse de proteger la privacidad de los datos personales.
- Sesgos: Ser consciente de los posibles sesgos en los datos y en las visualizaciones.
- Interpretación: Evitar sacar conclusiones apresuradas y asegurarse de que la visualización se interpreta correctamente.
Análisis de casos reales
Análisis de casos reales. Interpretación de visualizaciones existentes.
La visualización de datos es una herramienta poderosa para comunicar información compleja de manera sencilla y efectiva. Sin embargo, la interpretación correcta de una visualización requiere un análisis cuidadoso y una comprensión profunda de los datos y las técnicas de visualización utilizadas. En esta unidad, exploraremos varios casos reales de visualizaciones, analizando sus fortalezas, debilidades y las lecciones que podemos aprender de ellas.
¿Por qué es importante interpretar visualizaciones?
- Evitar conclusiones erróneas: Una interpretación incorrecta puede llevar a decisiones equivocadas.
- Identificar sesgos: Las visualizaciones pueden ser manipuladas para mostrar una determinada perspectiva.
- Apreciar la eficacia: Analizar visualizaciones exitosas puede inspirar nuevas ideas.
Elementos clave para interpretar una visualización
- Tipo de gráfico: Cada tipo de gráfico (barras, líneas, dispersión, etc.) está diseñado para mostrar diferentes tipos de relaciones entre los datos.
- Ejes: Los ejes deben estar claramente etiquetados y la escala debe ser apropiada.
- Colores: Los colores se utilizan para resaltar patrones y diferencias, pero un uso excesivo o inapropiado puede confundir.
- Leyendas: Las leyendas son esenciales para entender los diferentes elementos de la visualización.
- Contexto: El contexto en el que se presenta la visualización es crucial para su interpretación.
Casos de estudio
- Visualizaciones engañosas:Ejes truncados: Cómo los ejes pueden manipular la percepción de las diferencias.
- Colores engañosos: El uso de colores para enfatizar o minimizar ciertas tendencias.
- Gráficos 3D: Los desafíos de interpretar gráficos 3D y cómo pueden distorsionar los datos.
- Visualizaciones exitosas:The New York Times: Análisis de sus visualizaciones interactivas sobre temas como el cambio climático y las elecciones.
- Gapminder: Cómo Hans Rosling utilizó visualizaciones para desafiar los estereotipos y mostrar el progreso global.
- Florence Nightingale: Su innovadora visualización de datos para mejorar las condiciones sanitarias en los hospitales.
- Casos de uso en diferentes industrias:Marketing: Cómo las empresas utilizan visualizaciones para medir el rendimiento de sus campañas.
- Finanzas: Visualizaciones para analizar tendencias del mercado y tomar decisiones de inversión.
- Salud: Visualizaciones para estudiar la propagación de enfermedades y evaluar la eficacia de tratamientos.
Ejercicios prácticos
- Análisis de visualizaciones de noticias: Seleccionar una noticia con una visualización y analizarla en detalle.
- Creación de una visualización alternativa: Tomar una visualización existente y crear una versión alternativa que sea más clara y efectiva.
- Detección de sesgos en visualizaciones: Identificar ejemplos de sesgos en visualizaciones de los medios de comunicación.
Lecciones aprendidas
- La importancia del contexto: El contexto en el que se presenta una visualización es crucial para su interpretación.
- La necesidad de ser crítico: No todas las visualizaciones son lo que parecen.
- El poder de la visualización para contar historias: Las visualizaciones pueden comunicar información compleja de manera efectiva y atractiva.
Ejercicios guiados con
herramientas de visualización
Ejercicios guiados con herramientas de visualización. Creación de gráficos sencillos y complejos.
La mejor manera de aprender a utilizar una herramienta de visualización de datos es a través de la práctica. En esta unidad, te proporcionaremos una serie de ejercicios guiados que te permitirán aplicar los conceptos aprendidos y crear gráficos sencillos y complejos utilizando diferentes herramientas.
Ejercicios Guiados con Tableau
- Ejercicio 1: Gráfico de barras simpleCarga un conjunto de datos de ventas mensuales.
- Crea un gráfico de barras que muestre las ventas por producto.
- Personaliza el gráfico con colores, etiquetas y un título descriptivo.
- Ejercicio 2: Dashboard interactivoCrea un dashboard que muestre las ventas por región y por categoría de producto.
- Utiliza filtros para permitir a los usuarios explorar los datos de manera interactiva.
- Agrega un gráfico de líneas para mostrar la tendencia de ventas a lo largo del tiempo.
Ejercicios Guiados con Power BI
- Ejercicio 1: Mapa de calorCarga un conjunto de datos geográficos (por ejemplo, ventas por ciudad).
- Crea un mapa de calor para visualizar las ventas en diferentes regiones.
- Personaliza el mapa con diferentes colores y niveles de detalle.
- Ejercicio 2: Informe interactivoCrea un informe interactivo que incluya un gráfico de barras, un gráfico circular y una tabla.
- Utiliza paginas para organizar diferentes secciones del informe.
- Agrega filtros y slicers para permitir a los usuarios explorar los datos.
Ejercicios Guiados con Python (Matplotlib y Seaborn)
- Ejercicio 1: Gráfico de dispersiónGenera datos aleatorios para dos variables.
- Crea un gráfico de dispersión para visualizar la relación entre las dos variables.
- Personaliza el gráfico con títulos, etiquetas y una línea de tendencia.
- Ejercicio 2: HistogramaCarga un conjunto de datos numéricos (por ejemplo, edades).
- Crea un histograma para visualizar la distribución de los datos.
- Experimenta con diferentes números de bins y densidades.
Ejercicios Guiados con R (ggplot2)
- Ejercicio 1: Gráfico de líneas múltiplesCarga un conjunto de datos de series temporales.
- Crea un gráfico de líneas múltiples para comparar diferentes series.
- Personaliza el gráfico con colores, leyendas y títulos.
- Ejercicio 2: FacetingCarga un conjunto de datos con múltiples variables categóricas.
- Crea un gráfico facet para visualizar los datos en función de estas variables.
- Experimenta con diferentes tipos de faceting (wrap, grid).
Ejercicios Adicionales y Desafíos
- Creación de infografías: Utiliza herramientas como Canva o Piktochart para crear infografías atractivas y fáciles de entender.
- Visualización de datos geográficos: Utiliza herramientas como Leaflet o Mapbox para crear mapas interactivos.
- Análisis exploratorio de datos: Utiliza herramientas de visualización para descubrir patrones y tendencias en tus datos.
- Creación de dashboards para seguimiento de KPIs: Diseña dashboards personalizados para monitorear el desempeño de tu negocio.
Recursos Adicionales
- Tutoriales en línea: Plataformas como Coursera, Udemy y YouTube ofrecen una amplia variedad de tutoriales gratuitos y de pago.
- Comunidades en línea: Foros y grupos de usuarios en plataformas como Stack Overflow y Reddit son excelentes lugares para hacer preguntas y obtener ayuda.
- Documentación oficial: Consulta la documentación oficial de las herramientas que estás utilizando para obtener información detallada sobre las funciones y características.
Herramientas y Software
Consideraciones al elegir una herramienta
Consideraciones al elegir una herramienta. Facilidad de uso, funcionalidades, costo.
La elección de una herramienta de visualización de datos puede ser una tarea desafiante, dada la amplia variedad de opciones disponibles en el mercado. Cada herramienta ofrece un conjunto único de características y funcionalidades, diseñadas para satisfacer diferentes necesidades y niveles de experiencia. En esta unidad, exploraremos las principales consideraciones que debes tener en cuenta al seleccionar la herramienta adecuada para tu proyecto.
Facilidad de Uso
- Interfaz intuitiva: Busca herramientas con una interfaz de usuario clara y fácil de navegar, que te permita crear visualizaciones sin necesidad de conocimientos técnicos avanzados.
- Arrastrar y soltar: La capacidad de crear visualizaciones simplemente arrastrando y soltando elementos es una característica muy valiosa para usuarios sin experiencia en programación.
- Curva de aprendizaje: Evalúa la facilidad con la que puedes aprender a utilizar la herramienta. Una curva de aprendizaje suave te permitirá ser productivo rápidamente.
Funcionalidades
- Tipos de gráficos: Asegúrate de que la herramienta ofrezca los tipos de gráficos que necesitas para representar tus datos (barras, líneas, dispersión, mapas, etc.).
- Conectividad de datos: Verifica si la herramienta puede conectarse a las fuentes de datos que utilizas (bases de datos, hojas de cálculo, archivos CSV, etc.).
- Personalización: Evalúa la capacidad de personalizar los gráficos en términos de colores, estilos, etiquetas y otros elementos visuales.
- Interactividad: Si necesitas crear dashboards interactivos, busca herramientas que permitan a los usuarios explorar los datos de forma dinámica.
- Análisis avanzado: Algunas herramientas ofrecen funcionalidades avanzadas como análisis predictivo, modelado estadístico y machine learning.
Costo
- Licenciamiento: Considera los diferentes modelos de licenciamiento (suscripción mensual, anual, perpetua) y los costos asociados.
- Escalabilidad: Evalúa si el costo de la herramienta aumentará a medida que tus necesidades crezcan.
- Características adicionales: Algunas herramientas ofrecen características adicionales como almacenamiento en la nube, soporte técnico y capacitación, lo que puede incrementar el costo.
Otros Factores a Considerar
- Integración con otras herramientas: Si utilizas otras herramientas de análisis o software empresarial, verifica si la herramienta de visualización se integra con ellas.
- Comunidad de usuarios: Una comunidad activa puede proporcionar soporte, recursos y ejemplos de uso.
- Soporte técnico: Asegúrate de que la herramienta ofrezca un buen soporte técnico en caso de que necesites ayuda.
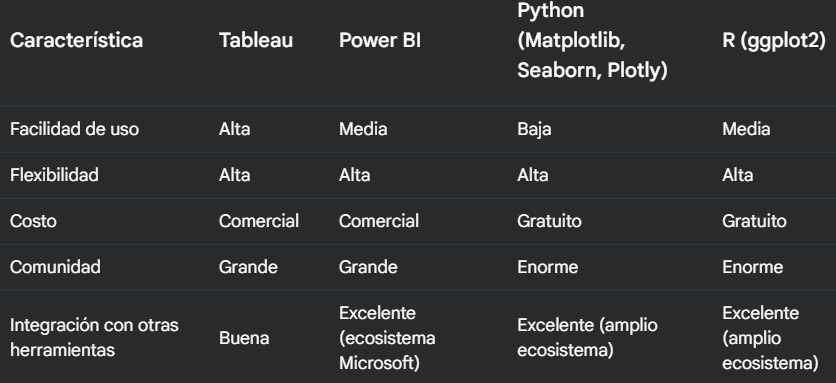
CaracterísticaTableauPower BIPython (Matplotlib, Seaborn, Plotly)R (ggplot2)Facilidad de usoAltaMediaBajaMediaFuncionalidadesAmpliasAmpliasMuy ampliasMuy ampliasCostoComercialComercialGratuitoGratuitoComunidadGrandeGrandeEnormeEnormeIntegraciónBuenaExcelente (ecosistema Microsoft)Excelente (amplio ecosistema)Excelente (amplio ecosistema)
Introducción a herramientas populares
Introducción a herramientas populares. Tableau, Power BI, Python (Matplotlib, Seaborn), R (ggplot2), etc.
En el panorama actual de la visualización de datos, una variedad de herramientas han surgido para satisfacer las diversas necesidades de los analistas y científicos de datos. Cada herramienta ofrece un conjunto único de características y funcionalidades, adaptándose a diferentes niveles de experiencia y tipos de proyectos. En esta unidad, exploraremos algunas de las herramientas más populares y sus características clave.
Tableau: La Estrella de la Visualización
- Características:Interfaz de arrastrar y soltar intuitiva
- Amplia gama de gráficos y visualizaciones
- Conexión a múltiples fuentes de datos
- Capacidad de crear dashboards interactivos
- Ventajas:Fácil de aprender y usar
- Gran comunidad de usuarios
- Ideal para análisis exploratorio y creación de dashboards
- Desventajas:Costo puede ser elevado para usuarios individuales
- Curva de aprendizaje para funcionalidades avanzadas
Power BI: La Opción de Microsoft
- Características:Integración profunda con el ecosistema de Microsoft
- Amplias capacidades de modelado de datos
- Servicio en la nube y aplicaciones móviles
- Ventajas:Ideal para organizaciones que utilizan productos de Microsoft
- Funcionalidades avanzadas de análisis
- Desventajas:Interfaz puede resultar compleja para usuarios principiantes
- Algunas funcionalidades requieren licencias adicionales
Python: La Flexibilidad del Código
- Bibliotecas:Matplotlib: Biblioteca base para crear gráficos estáticos, personalizables y de alta calidad.
- Seaborn: Construido sobre Matplotlib, ofrece una interfaz de alto nivel para crear gráficos estadísticos atractivos.
- Plotly: Crea gráficos interactivos y dashboards que se pueden exportar a diferentes formatos.
- Ventajas:Gran flexibilidad y personalización
- Comunidad activa y amplia documentación
- Ideal para análisis de datos complejos y científicos
- Desventajas:Requiere conocimientos de programación
- Curva de aprendizaje más pronunciada
R: El Líder en Estadística y Ciencia de Datos
- Biblioteca ggplot2:Inspirada en el libro "The Grammar of Graphics"
- Permite crear gráficos elegantes y personalizados a través de capas
- Ventajas:Ideal para análisis estadísticos y gráficos científicos
- Gran comunidad y paquetes adicionales
- Desventajas:Curva de aprendizaje más pronunciada que Tableau o Power BI
- Sintaxis puede ser más compleja para principiantes
Cuándo Utilizar Cada Herramienta
- Tableau: Ideal para análisis exploratorio, creación de dashboards interactivos y visualización de datos empresariales.
- Power BI: Perfecto para organizaciones que utilizan productos de Microsoft y necesitan una solución integrada.
- Python (Matplotlib, Seaborn, Plotly): Ideal para científicos de datos, ingenieros y aquellos que necesitan una gran flexibilidad y personalización.
- R (ggplot2): Perfecto para análisis estadísticos y gráficos científicos, especialmente para aquellos familiarizados con el lenguaje R.
Panorama general de las
herramientas de visualización
Panorama general de las herramientas de visualización. Desde hojas de cálculo hasta software especializado.
La visualización de datos ha evolucionado considerablemente en los últimos años, gracias a la proliferación de herramientas y software especializados. En esta unidad, exploraremos el panorama general de las herramientas disponibles para crear visualizaciones, desde las más básicas hasta las más sofisticadas, y discutiremos sus características clave y aplicaciones.
Hojas de Cálculo: El Punto de Partida
- Excel: La herramienta más utilizada para crear gráficos básicos como barras, líneas y dispersión.
- Ventajas: Familiaridad, facilidad de uso, integración con otras herramientas de Microsoft Office.
- Limitaciones: Funcionalidad limitada para visualizaciones más complejas, dificultad para crear dashboards interactivos.
- Google Sheets: Alternativa gratuita a Excel con funcionalidades similares y colaboración en tiempo real.
- Ventajas: Gratuito, fácil de usar, integración con Google Drive.
- Limitaciones: Menos opciones de personalización que Excel.
Software de Visualización Especializado
- Tableau: Una de las herramientas más populares para crear visualizaciones interactivas y dashboards.
- Ventajas: Facilidad de uso, gran variedad de gráficos, capacidad de conectar con múltiples fuentes de datos.
- Limitaciones: Costo, curva de aprendizaje algo pronunciada.
- Power BI: Otra herramienta poderosa de Microsoft, especialmente integrada con el ecosistema de Microsoft.
- Ventajas: Integración con otras herramientas de Microsoft, capacidad de crear informes interactivos.
- Limitaciones: Curva de aprendizaje similar a Tableau.
- Qlik Sense: Conocido por su capacidad de asociar datos de diferentes fuentes y crear aplicaciones analíticas.
- Ventajas: Asociación de datos, análisis asociativo, creación de aplicaciones.
- Limitaciones: Interfaz puede resultar compleja para usuarios principiantes.
- R y Python: Lenguajes de programación de código abierto con una amplia gama de paquetes para visualización de datos (ggplot2, seaborn, Plotly).
- Ventajas: Gran flexibilidad, personalización, comunidad activa.
- Limitaciones: Requiere conocimientos de programación.
Herramientas de Visualización en Línea
- Google Charts: Biblioteca gratuita de gráficos para incrustar en páginas web.
- Ventajas: Gratuito, fácil de usar, integración con Google Apps.
- Limitaciones: Funcionalidad limitada en comparación con otras herramientas.
- Datawrapper: Herramienta en línea para crear gráficos de alta calidad de forma rápida y sencilla.
- Ventajas: Fácil de usar, plantillas prediseñadas, opción de exportar gráficos en diferentes formatos.
- Limitaciones: Funcionalidad limitada para análisis de datos complejos.
Herramientas de Infografías
- Canva: Herramienta de diseño gráfico con plantillas prediseñadas para crear infografías.
- Ventajas: Fácil de usar, gran variedad de plantillas, ideal para usuarios sin conocimientos de diseño.
- Limitaciones: Menos orientada a datos complejos que otras herramientas.
- Piktochart: Otra herramienta popular para crear infografías y presentaciones visuales.
- Ventajas: Interfaz intuitiva, gran variedad de gráficos y elementos visuales.
- Limitaciones: Menos opciones de personalización que otras herramientas.
Factores a Considerar al Elegir una Herramienta
- Tipo de datos: ¿Qué tipo de datos vas a visualizar?
- Complejidad de la visualización: ¿Necesitas gráficos simples o interactivos?
- Conocimientos técnicos: ¿Tienes experiencia en programación o prefieres una herramienta de arrastrar y soltar?
- Presupuesto: ¿Cuál es tu presupuesto?
- Colaboración: ¿Necesitas compartir tus visualizaciones con otros?
Aplicaciones Prácticas en el Mundo Real
Aplicaciones Prácticas en el Mundo Real
Visualización de datos en diferentes industrias. Ejemplos en negocios, salud, ciencia, gobierno, etc.
Casos de éxito y fracasos. Análisis de visualizaciones efectivas e inefectivas.
Ética en la visualización de datos. Cómo evitar la manipulación de datos y la desinformación.
Ética en la visualización de datos
Ética en la visualización de datos. Cómo evitar la manipulación de datos y la desinformación.
La visualización de datos es una herramienta poderosa que puede influir en la opinión pública y la toma de decisiones. Sin embargo, si no se utiliza de manera ética, puede llevar a la manipulación de datos y la desinformación. En esta unidad, exploraremos los principios éticos de la visualización de datos y cómo evitar prácticas engañosas.
¿Qué es la Ética en la Visualización de Datos?
- Definición: La ética en la visualización de datos se refiere a los principios morales que guían la creación y presentación de visualizaciones, asegurando que sean precisas, justas y no engañosas.
- Importancia: La ética en la visualización de datos es crucial para mantener la integridad de la información y fomentar la confianza en los datos.
Principios Éticos Clave
- Veracidad: Los datos presentados deben ser precisos y completos.
- Objetividad: Evitar sesgos personales o ideológicos al seleccionar y presentar los datos.
- Transparencia: Explicar claramente cómo se obtuvieron y procesaron los datos.
- Contexto: Proporcionar suficiente contexto para que los espectadores puedan interpretar los datos correctamente.
- Claridad: Las visualizaciones deben ser fáciles de entender y no deben engañar al espectador.
Prácticas Deshonestas a Evitar
- Manipulación de ejes: Alterar los ejes para exagerar o minimizar las diferencias.
- Selección de datos: Presentar solo los datos que respaldan una determinada narrativa.
- Uso de colores engañosos: Utilizar colores para influir en la percepción de los datos.
- Gráficos tridimensionales engañosos: Distorsionar las proporciones y dificultar la comparación.
- Falta de contexto: Presentar datos sin el contexto necesario para interpretarlos correctamente. [Image: Ejemplos de gráficos que manipulan los datos]
Cómo Garantizar una Visualización Ética
- Comprender los datos: Asegurarse de entender completamente los datos antes de crear una visualización.
- Elegir el gráfico adecuado: Seleccionar el tipo de gráfico que mejor represente los datos y el mensaje.
- Utilizar colores y escalas de manera adecuada: Evitar colores engañosos y escalas que distorsionen los datos.
- Proporcionar suficiente contexto: Explicar claramente cómo se obtuvieron los datos y qué significan.
- Revisar la visualización con un ojo crítico: Preguntarse si la visualización es clara, precisa y no engañosa.
Casos Reales de Manipulación de Datos
- Censo de los Estados Unidos: A lo largo de la historia, el censo de los Estados Unidos ha sido objeto de manipulaciones para favorecer a ciertos grupos o políticas.
- Publicidad engañosa: Muchas empresas utilizan gráficos engañosos para exagerar los beneficios de sus productos.
- Política: Los políticos a menudo utilizan gráficos para respaldar sus argumentos, incluso cuando los datos no los respaldan completamente.
El Papel del Diseño en la Ética
- Diseño ético: El diseño de una visualización puede influir en la forma en que los espectadores interpretan los datos.
- Responsabilidad del diseñador: Los diseñadores tienen la responsabilidad de crear visualizaciones que sean claras, precisas y no engañosas.
Conclusión
La ética en la visualización de datos es fundamental para garantizar la integridad de la información y fomentar la confianza en los datos. Al seguir los principios éticos y evitar prácticas engañosas, podemos crear visualizaciones que sean informativas, precisas y justas.
¿Te gustaría profundizar en algún aspecto específico de la ética en la visualización de datos o explorar ejemplos más detallados?
Posibles temas a explorar en futuras unidades:
- La ética en la inteligencia artificial y la visualización de datos
- El papel de los medios de comunicación en la difusión de visualizaciones engañosas
- Cómo detectar visualizaciones engañosas
Casos de éxito y fracasos
Casos de éxito y fracasos. Análisis de visualizaciones efectivas e inefectivas.
La visualización de datos es una herramienta poderosa, pero su efectividad depende en gran medida de cómo se aplica. En esta unidad, exploraremos casos reales de visualizaciones, tanto exitosas como fallidas, para comprender los principios que hacen que una visualización sea efectiva y las trampas que deben evitarse.
Casos de Éxito: Lo que Funciona
- Visualizaciones que cuentan historias:The New York Times: Sus visualizaciones interactivas sobre temas como el cambio climático y las elecciones presidenciales han sido ampliamente reconocidas por su capacidad para contar historias complejas de manera clara y atractiva.
- Gapminder: Hans Rosling y su equipo utilizaron visualizaciones innovadoras para desafiar los estereotipos y mostrar el progreso global en temas como la salud y la pobreza. [Image: Ejemplo de una visualización de Gapminder]
- Dashboards interactivos:Google Analytics: Permite a los marketers analizar el rendimiento de sus campañas y tomar decisiones basadas en datos en tiempo real.
- Tableau Public: Una plataforma donde usuarios de todo el mundo comparten sus visualizaciones, mostrando la versatilidad de esta herramienta para diferentes industrias. [Image: Ejemplo de un dashboard de Google Analytics]
- Infografías:National Geographic: Sus infografías son conocidas por su diseño atractivo y su capacidad para comunicar información compleja de manera sencilla.
- The Economist: Utiliza infografías para explicar temas económicos y políticos de manera visualmente atractiva. [Image: Ejemplo de una infografía de National Geographic]
Casos de Fracaso: Lo que No Funciona
- Sobrecarga de información:Gráficos con demasiados datos: Dificultan la comprensión y distraen al espectador.
- Uso excesivo de colores y efectos: Crean una sensación de desorden y dificultan la lectura. [Image: Ejemplo de un gráfico sobrecargado de información]
- Escalas engañosas:Ejes truncados: Distorsionan las diferencias entre los valores.
- Uso inadecuado de áreas: Crean una impresión errónea de las proporciones. [Image: Ejemplo de un gráfico con una escala engañosa]
- Falta de contexto:Gráficos sin títulos ni etiquetas: Dificultan la interpretación de los datos.
- Datos sin referencia: No permiten comparar los resultados con otros datos o benchmarks. [Image: Ejemplo de un gráfico sin contexto]
Lecciones Aprendidas
- La importancia de la historia: Una buena visualización cuenta una historia clara y concisa.
- La simplicidad es clave: Menos es más. Evita la sobrecarga de información y elige los gráficos adecuados.
- El contexto es fundamental: Proporciona suficiente contexto para que el espectador pueda interpretar los datos.
- La estética importa: Una visualización atractiva es más fácil de recordar y compartir.
- La interactividad mejora la experiencia: Permite a los usuarios explorar los datos a su propio ritmo.
Análisis de los Casos
- ¿Qué hace que una visualización sea exitosa?Claridad, concisión, relevancia, estética, interactividad.
- ¿Cuáles son los errores más comunes?Sobrecarga de información, escalas engañosas, falta de contexto, diseño pobre.
- ¿Cómo podemos evitar estos errores?Planificar la visualización antes de comenzar, elegir los gráficos adecuados, utilizar herramientas de diseño, pedir feedback.
Conclusión
Al analizar casos de éxito y fracaso, podemos aprender valiosas lecciones sobre cómo crear visualizaciones efectivas. La clave está en combinar la belleza y la funcionalidad, y en contar una historia que resuene con la audiencia.
¿Te gustaría profundizar en algún caso específico o explorar otros ejemplos?
Posibles temas a explorar en futuras unidades:
- Visualizaciones engañosas y cómo identificarlas
- Mejores prácticas para la creación de dashboards interactivos
- El futuro de la visualización de datos
Visualización de datos
en diferentes industrias
Visualización de datos en diferentes industrias. Ejemplos en negocios, salud, ciencia, gobierno, etc.
La visualización de datos ha revolucionado la forma en que las industrias analizan información y toman decisiones. Al transformar datos complejos en representaciones visuales, las empresas pueden identificar patrones, tendencias y oportunidades de manera más rápida y efectiva. En esta unidad, exploraremos cómo la visualización de datos se aplica en diversas industrias, desde los negocios hasta la ciencia.
Visualización de Datos en los Negocios
- Análisis de ventas: Identificar productos más vendidos, tendencias de mercado y oportunidades de crecimiento.
- Gestión de clientes: Segmentar clientes, analizar el comportamiento de compra y mejorar la experiencia del cliente.
- Marketing digital: Medir el rendimiento de las campañas, optimizar el presupuesto y conocer a la audiencia.
- Finanzas: Visualizar indicadores clave de rendimiento (KPI), detectar fraudes y predecir tendencias financieras. [Image: Ejemplo de un dashboard de ventas interactivo]
Visualización de Datos en la Salud
- Análisis de registros médicos: Identificar patrones en enfermedades, desarrollar tratamientos personalizados y mejorar la eficiencia de los hospitales.
- Investigación biomédica: Visualizar datos genómicos, proteómicos y de imágenes médicas para descubrir nuevos tratamientos.
- Epidemiología: Monitorear la propagación de enfermedades y evaluar el impacto de las intervenciones de salud pública. [Image: Ejemplo de una visualización de datos genómicos]
Visualización de Datos en la Ciencia
- Exploración de datos: Visualizar grandes conjuntos de datos para descubrir patrones y relaciones.
- Modelado y simulación: Visualizar resultados de modelos matemáticos y simulaciones.
- Gestión de proyectos científicos: Seguimiento del progreso de los proyectos y colaboración entre investigadores. [Image: Ejemplo de una visualización de datos astronómicos]
Visualización de Datos en el Gobierno
- Planificación urbana: Analizar el uso del suelo, el tráfico y otros datos urbanos para mejorar la calidad de vida.
- Política pública: Evaluar el impacto de las políticas públicas y tomar decisiones basadas en datos.
- Seguridad nacional: Monitorear amenazas y detectar patrones de comportamiento sospechoso. [Image: Ejemplo de un mapa de calor que muestra la densidad de población]
Visualización de Datos en Otras Industrias
- Educación: Analizar el rendimiento de los estudiantes, identificar áreas de mejora y personalizar el aprendizaje.
- Medio ambiente: Monitorear el cambio climático, analizar la calidad del aire y del agua, y gestionar los recursos naturales.
- Deportes: Analizar el rendimiento de los atletas, optimizar las estrategias de entrenamiento y mejorar el desempeño de los equipos.
Herramientas y Técnicas Comunes
- Dashboards interactivos: Permiten a los usuarios explorar los datos de manera dinámica.
- Mapas: Visualizan datos geográficos y espaciales.
- Gráficos de red: Representan relaciones entre entidades.
- Visualizaciones de tiempo: Muestra cómo los datos cambian a lo largo del tiempo.
- Inteligencia artificial: Automatiza la creación de visualizaciones y descubre insights ocultos.
Desafíos y Consideraciones
- Calidad de los datos: La calidad de los datos es fundamental para la visualización efectiva.
- Privacidad de los datos: Es necesario proteger la privacidad de los datos personales.
- Interpretación de los datos: La visualización no debe sesgar la interpretación de los datos.
Conclusión
La visualización de datos se ha convertido en una herramienta indispensable en todas las industrias. Al transformar datos complejos en representaciones visuales, las organizaciones pueden tomar decisiones más informadas, mejorar la eficiencia y obtener una ventaja competitiva.
¿Te gustaría profundizar en alguna industria en particular o explorar ejemplos más detallados?
Posibles temas a explorar en futuras unidades:
- Visualización de datos en tiempo real
- Ética en la visualización de datos
- Tendencias futuras en la visualización de datos
Diseño y Estética
Diseño y Estética
Principios del diseño de la información. Claridad, concisión, coherencia.
La importancia del color, la tipografía y el espacio en blanco. Cómo estos elementos afectan la percepción.
Creación de narrativas visuales. Cómo contar una historia a través de los datos.
Creación de narrativas visuales
Creación de narrativas visuales. Cómo contar una historia a través de los datos.
La visualización de datos no se limita a presentar números y gráficos; es una herramienta poderosa para contar historias y comunicar ideas de manera efectiva. La creación de narrativas visuales implica transformar datos en una secuencia lógica que guíe al espectador a través de una historia. En esta unidad, exploraremos cómo construir narrativas visuales impactantes y persuasivas.
¿Qué es una Narrativa Visual?
- Definición: Una narrativa visual es una secuencia de visualizaciones que cuentan una historia.
- Objetivo: Comunicar un mensaje claro y conciso a través de los datos.
- Elementos:Introducción: Presenta el contexto y la pregunta central.
- Desarrollo: Despliega los datos de manera lógica, destacando los puntos clave.
- Conclusión: Resume los hallazgos principales y ofrece una perspectiva.
Cómo Construir una Narrativa Visual
- Identificar la historia: ¿Cuál es el mensaje principal que quieres transmitir?
- Seleccionar los datos relevantes: ¿Qué datos apoyan tu historia?
- Crear una estructura narrativa: Define la secuencia de las visualizaciones.
- Elegir los tipos de gráficos adecuados: Cada gráfico debe cumplir un propósito específico.
- Utilizar elementos de diseño: Color, tipografía, espacio en blanco para enfatizar los puntos clave.
- Incluir texto explicativo: El texto debe complementar las visualizaciones, no duplicarlas.
- Crear una experiencia interactiva: Permite al espectador explorar los datos de forma dinámica.
Elementos Clave de una Narrativa Visual Efectiva
- Claridad: Cada visualización debe ser fácil de entender.
- Coherencia: Las visualizaciones deben fluir de manera lógica.
- Concisión: Evita la sobrecarga de información.
- Impacto: Despierta el interés y la emoción del espectador.
Técnicas para Mejorar la Narrativa Visual
- Storyboarding: Planifica la secuencia de las visualizaciones.
- Jerarquía visual: Guía la atención del espectador hacia los elementos más importantes.
- Transiciones suaves: Crea una experiencia fluida al pasar de una visualización a otra.
- Uso de metáforas visuales: Transforma conceptos abstractos en imágenes concretas.
- Interactividad: Permite al espectador explorar los datos a su propio ritmo.
Ejemplos de Narrativas Visuales Efectivas
- Casos de éxito: Análisis de campañas de marketing exitosas basadas en datos.
- Estudios de caso: Exploración de problemas del mundo real y cómo los datos pueden ayudar a encontrar soluciones.
- Tableros de control interactivos: Visualización de datos en tiempo real para tomar decisiones informadas.
Herramientas para Crear Narrativas Visuales
- Software especializado: Tableau, Power BI, R, Python
- Herramientas de presentación: PowerPoint, Google Slides
Conclusión
La creación de narrativas visuales es una habilidad esencial para comunicar ideas de manera efectiva a través de los datos. Al seguir estos principios y utilizar las herramientas adecuadas, puedes transformar datos complejos en historias poderosas que inspiren y persuadan.
¿Te gustaría profundizar en algún aspecto específico de la creación de narrativas visuales o explorar ejemplos más detallados?
Posibles temas a explorar en futuras unidades:
- Narrativas visuales interactivas
- La importancia del contexto en la narrativa visual
- Cómo combinar datos cualitativos y cuantitativos en una narrativa visual
- Ética en la visualización de datos
La importancia del color, la
tipografía y el espacio en blanco
La importancia del color, la tipografía y el espacio en blanco. Cómo estos elementos afectan la percepción.
El diseño de una visualización de datos va más allá de simplemente representar datos. Los elementos visuales como el color, la tipografía y el espacio en blanco juegan un papel fundamental en cómo los espectadores perciben y comprenden la información. En esta unidad, exploraremos cómo estos elementos afectan la percepción y cómo utilizarlos de manera efectiva para crear visualizaciones impactantes.
El Color: Más que una Decoración
- Psicología del color: Los colores evocan emociones y asociaciones culturales.
- Colores cálidos: Rojo, naranja, amarillo: asociadas con energía, pasión, calor.
- Colores fríos: Azul, verde, violeta: asociadas con calma, tranquilidad, confianza.
- Colores neutros: Blanco, negro, gris: proporcionan equilibrio y sofisticación. [Image of: Rueda de color y ejemplos de cómo los colores afectan las emociones]
- Jerarquía visual: El color puede destacar elementos importantes y guiar la atención del espectador.
- Legibilidad: La combinación de colores debe garantizar una buena legibilidad.
La Tipografía: Más que Letras
- Legibilidad: La elección de la fuente afecta la facilidad de lectura.
- Jerarquía: Las diferentes fuentes pueden crear jerarquías visuales.
- Personalidad: La tipografía puede transmitir una sensación de formalidad, informalidad, modernidad, etc. [Image of: Ejemplos de diferentes tipos de fuentes y su impacto visual]
- Emparejamiento de fuentes: Combinar fuentes de manera efectiva para crear una composición armoniosa.
El Espacio en Blanco: El Respiro de la Visualización
- Claridad: El espacio en blanco mejora la legibilidad y reduce la saturación visual.
- Jerarquía: El espacio en blanco puede resaltar elementos importantes.
- Respiración: Permite a los espectadores descansar la vista y procesar la información. [Image of: Ejemplos de cómo el espacio en blanco mejora la legibilidad]
La Interacción entre Color, Tipografía y Espacio en Blanco
- Armonía: Estos elementos deben trabajar juntos para crear una composición cohesiva.
- Contraste: El contraste entre elementos puede resaltar información importante.
- Equilibrio: Una distribución equilibrada de los elementos crea una sensación de armonía.
Ejemplos Prácticos
- Análisis de diferentes paletas de colores: Cómo los colores afectan la percepción de los datos.
- Comparación de diferentes tipos de fuentes: Cómo la tipografía influye en la legibilidad y la estética.
- Estudio de casos: Análisis de visualizaciones exitosas y fallidas en términos de uso del color, tipografía y espacio en blanco.
Herramientas para Crear Visualizaciones Efectivas
- Software especializado: Tableau, Power BI, R, Python
- Hojas de cálculo: Excel, Google Sheets
Conclusión
El color, la tipografía y el espacio en blanco son elementos fundamentales en el diseño de visualizaciones de datos. Al utilizar estos elementos de manera efectiva, podemos crear visualizaciones que sean no solo informativas, sino también estéticamente agradables y memorables.
¿Te gustaría profundizar en algún elemento específico o explorar ejemplos más detallados?
Posibles temas a explorar en futuras unidades:
- Teoría del color y su aplicación en la visualización de datos
- La psicología de la tipografía
- Diseño de paletas de colores personalizadas
- Cómo crear narrativas visuales efectivas utilizando el color y la tipografía
Principios del diseño de la información
Principios del diseño de la información. Claridad, concisión, coherencia.
El diseño de la información es fundamental para crear visualizaciones de datos efectivas. Los principios de claridad, concisión y coherencia son esenciales para garantizar que nuestras visualizaciones sean fáciles de entender, transmitan la información de manera clara y sean visualmente atractivas. En esta unidad, exploraremos cómo aplicar estos principios a la visualización de datos.
Claridad: La Facilidad de Entender
- Definiciones claras: Cada elemento visual debe tener una definición clara y un significado único.
- Jerarquía visual: Guía la atención del espectador hacia los elementos más importantes.
- Etiquetado preciso: Los ejes, leyendas y títulos deben ser claros y concisos.
- Colores y contrastes adecuados: Utiliza colores que faciliten la distinción entre elementos.
- Tipografía legible: Elige fuentes que sean fáciles de leer y que se adapten al contexto. [Image of: Ejemplo de una visualización clara vs. una confusa]
Concisión: La Esencia del Mensaje
- Eliminar lo innecesario: Elimina cualquier elemento que no sea esencial para comunicar el mensaje principal.
- Simplificar la información: Evita la sobrecarga de información y presenta los datos de manera concisa.
- Priorizar la información: Destaca los hallazgos más importantes.
- Utilizar gráficos adecuados: Elige el tipo de gráfico que mejor represente los datos y el mensaje. [Image of: Ejemplo de una visualización concisa vs. una sobrecargada]
Coherencia: La Unidad del Diseño
- Estilo visual consistente: Utiliza un estilo visual uniforme en toda la visualización.
- Relación entre elementos: Los elementos visuales deben estar relacionados entre sí de manera lógica.
- Flujo visual: Guía al espectador a través de la visualización de manera natural.
- Jerarquía visual consistente: Mantén una jerarquía visual consistente en toda la visualización. [Image of: Ejemplo de una visualización con coherencia visual]
La Importancia de la Percepción Visual
- Ley de la pregnancia: Tendemos a percibir las formas de la manera más simple y organizada posible.
- Ley de proximidad: Elementos cercanos se perciben como un grupo.
- Ley de semejanza: Elementos similares se perciben como un grupo.
- Ley de continuidad: Tendemos a seguir líneas o curvas suaves.
- Ley de cierre: Tendemos a completar formas incompletas.
- Figura-fondo: Separamos los objetos de su entorno. [Image of: Ejemplos de las leyes de la percepción visual aplicadas a gráficos]
Ejemplos Prácticos
- Comparación de diferentes visualizaciones: Análisis de cómo la claridad, concisión y coherencia afectan la comprensión.
- Casos de éxito y fracaso: Identificación de los principios aplicados y los errores cometidos.
Herramientas para Crear Visualizaciones Efectivas
- Software especializado: Tableau, Power BI, R, Python
- Hojas de cálculo: Excel, Google Sheets
Conclusión
La claridad, concisión y coherencia son principios fundamentales del diseño de la información que deben aplicarse a todas las visualizaciones de datos. Al seguir estos principios, podemos crear visualizaciones que sean no solo estéticamente agradables, sino también altamente informativas y persuasivas.
¿Te gustaría profundizar en algún principio específico o explorar ejemplos más detallados?
Posibles temas a explorar en futuras unidades:
- El papel del color en la visualización de datos
- La importancia de la tipografía en la visualización
- Cómo crear narrativas visuales efectivas
Fundamentos Teóricos
Fundamentos Teóricos
- Principios de la percepción visual. Cómo el cerebro procesa la información visual.
- Elementos básicos de un gráfico. Tipos de gráficos, ejes, escalas, leyendas, etc.
- Tipos de datos y su representación visual. Datos numéricos, categóricos, temporales, geográficos.
- La elección del gráfico adecuado. Cómo seleccionar el tipo de gráfico más efectivo para comunicar la información.
La elección del gráfico adecuado
La elección del gráfico adecuado. Cómo seleccionar el tipo de gráfico más efectivo para comunicar la información.
La elección del gráfico adecuado es una decisión crucial en la visualización de datos. Un gráfico bien seleccionado puede transformar datos complejos en información fácilmente comprensible, mientras que una elección equivocada puede llevar a conclusiones erróneas. En esta unidad, exploraremos los factores clave a considerar al seleccionar el tipo de gráfico más efectivo para comunicar tu mensaje.
Factores a Considerar al Elegir un Gráfico
- Tipo de datos: ¿Son numéricos, categóricos, temporales o geográficos?
- Mensaje a comunicar: ¿Qué quieres destacar? Tendencias, comparaciones, distribuciones, relaciones?
- Audiencia: ¿Cuál es el nivel de conocimiento técnico de tu audiencia?
- Número de variables: ¿Cuántas variables quieres representar?
- Complejidad de los datos: ¿Los datos son simples o complejos?
Preguntas Clave para Guiar tu Elección
- ¿Quiero comparar categorías?
- ¿Quiero mostrar una tendencia a lo largo del tiempo?
- ¿Quiero mostrar la distribución de los datos?
- ¿Quiero mostrar la relación entre dos variables?
- ¿Quiero mostrar partes de un todo?
- ¿Quiero representar datos geográficos?
Matriz de Decisión para la Selección de Gráficos
Pregunta Tipo de Gráfico Sugerido
Comparación de categorías Gráfico de barras, gráfico circular
Tendencia a lo largo del tiempo Gráfico de líneas, gráfico de área
Distribución de datos Histograma, diagrama de caja
Relación entre dos variables Diagrama de dispersión
Partes de un todo Gráfico circular
Datos geográficos Mapa
Ejemplos Prácticos
- Comparar las ventas de diferentes productos: Gráfico de barras
- Mostrar la evolución del precio de una acción a lo largo del tiempo: Gráfico de líneas
- Visualizar la distribución de edades en una población: Histograma
- Mostrar la relación entre el tamaño de una casa y su precio: Diagrama de dispersión
- Representar la proporción de votos por candidato: Gráfico circular
- Visualizar la densidad de población en un país: Mapa coropleta
Consideraciones Adicionales
- Estética: Un gráfico atractivo facilita la comprensión.
- Interactividad: Permite a los usuarios explorar los datos de forma más profunda.
- Contexto: Proporciona suficiente contexto para interpretar los datos.
Errores Comunes a Evitar
- Sobrecarga de información: Demasiados datos en un solo gráfico.
- Escalas engañosas: Manipulación de las escalas para distorsionar los datos.
- Uso incorrecto del color: Dificulta la distinción entre elementos.
- Gráficos tridimensionales excesivos: Pueden dificultar la lectura.
Conclusión
La elección del gráfico adecuado es un arte que requiere tanto conocimiento técnico como habilidades de comunicación visual. Al seguir estos principios y considerar los factores mencionados, podrás crear visualizaciones que sean claras, concisas y efectivas.
¿Te gustaría profundizar en algún aspecto específico de la elección de gráficos o explorar ejemplos más detallados?
Posibles temas a explorar en futuras unidades:
- Visualización de datos multivariados
- Creación de dashboards interactivos
- Ética en la visualización de datos
Tipos de datos y su representación visual
Tipos de datos y su representación visual. Datos numéricos, categóricos, temporales, geográficos.
La elección del tipo de gráfico adecuado es crucial para una visualización efectiva. La naturaleza de los datos, ya sean numéricos, categóricos, temporales o geográficos, determina la mejor manera de representarlos visualmente. En esta unidad, exploraremos los diferentes tipos de datos y los gráficos más adecuados para cada uno.
Tipos de Datos
- Datos Numéricos: Representan cantidades o medidas.
- Discretos: Valores enteros (ej: número de ventas, cantidad de productos).
- Continuos: Pueden tomar cualquier valor dentro de un intervalo (ej: altura, peso, temperatura).
- Datos Categóricos: Representan grupos o categorías.
- Nominales: No hay un orden inherente (ej: color, género).
- Ordinales: Existe un orden natural (ej: niveles de satisfacción, calificaciones).
- Datos Temporales: Representan eventos que ocurren en un momento específico.
- Datos Geográficos: Relacionados con ubicaciones en un mapa.
Representación Visual de Datos Numéricos
- Gráficos de barras: Comparación de categorías numéricas.
- Histogramas: Distribución de datos numéricos continuos.
- Gráficos de líneas: Tendencias a lo largo del tiempo.
- Diagramas de dispersión: Relación entre dos variables numéricas.
[Image of: Ejemplos de gráficos de barras, histogramas, líneas y dispersión]
Representación Visual de Datos Categóricos
- Gráficos de barras: Comparación de frecuencias entre categorías.
- Gráficos circulares: Proporción de cada categoría dentro del total.
- Gráficos de barras apiladas: Comparación de múltiples categorías.
[Image of: Ejemplos de gráficos de barras, circulares y apilados para datos categóricos]
Representación Visual de Datos Temporales
- Gráficos de líneas: Evolución de una variable a lo largo del tiempo.
- Gráficos de área: Visualización de acumulados a lo largo del tiempo.
[Image of: Ejemplos de gráficos de líneas y área para datos temporales]
Representación Visual de Datos Geográficos
- Mapas:Coropletas: Utilizan colores para representar valores en áreas geográficas.
- De puntos: Representan ubicaciones exactas.
- De flujo: Muestran movimientos o flujos entre ubicaciones.
[Image of: Ejemplos de mapas coropletas, de puntos y de flujo]
Principios para Seleccionar el Gráfico Adecuado
- Tipo de datos: El tipo de gráfico debe coincidir con el tipo de datos.
- Mensaje a comunicar: ¿Qué quieres mostrar?
- Audiencia: ¿Quién verá el gráfico?
- Complejidad: Evita gráficos demasiado complejos.
- Estética: Un buen diseño mejora la comprensión.
Herramientas para Crear Visualizaciones
- Hojas de cálculo: Excel, Google Sheets
- Software especializado: Tableau, Power BI, R, Python
Conclusión
La elección del tipo de gráfico adecuado es fundamental para una visualización efectiva. Al comprender los diferentes tipos de datos y sus representaciones visuales, podrás comunicar tus hallazgos de manera clara y concisa.
¿Te gustaría profundizar en algún tipo de dato en particular o explorar ejemplos más detallados?
Posibles temas a explorar en futuras unidades:
- Visualización de datos multivariados
- Creación de dashboards interactivos
- Ética en la visualización de datos
Elementos básicos de un gráfico
Elementos básicos de un gráfico. Tipos de gráficos, ejes, escalas, leyendas, etc.
Un gráfico es más que una simple imagen; es una herramienta poderosa para comunicar información de manera concisa y efectiva. Cada elemento que compone un gráfico juega un papel crucial en la transmisión de los datos y en la interpretación que hace el espectador. En esta unidad, exploraremos los elementos básicos de un gráfico y cómo utilizarlos de manera estratégica para crear visualizaciones impactantes.
Los Componentes Esenciales de un Gráfico
- Título:Función: Resume el contenido del gráfico de manera clara y concisa.
- Ubicación: Generalmente en la parte superior del gráfico.
- Importancia: Proporciona al espectador una primera impresión rápida del tema.
- Ejes:Eje X: Representa la variable independiente o categoría.
- Eje Y: Representa la variable dependiente o valor numérico.
- Escalas:Lineales: La distancia entre los valores es proporcional a la diferencia entre ellos.
- Logarítmicas: Útil para representar rangos de valores muy grandes.
- Categóricas: Para representar categorías o grupos. [Image of: Ejemplo de ejes lineales, logarítmicos y categóricos]
- Etiquetas:Ejes: Identifican las variables representadas en cada eje.
- Datos: Proporcionan información adicional sobre los puntos de datos.
- Leyenda:Explica los símbolos, colores o patrones utilizados en el gráfico.
- Ubicación: Generalmente en una esquina del gráfico.
- Área del gráfico:Espacio donde se representan los datos.
- Título de datos:Identifica cada conjunto de datos o serie.
Tipos de Gráficos y su Uso
- Gráficos de barras: Comparación de categorías.
- Gráficos de líneas: Mostrar tendencias a lo largo del tiempo.
- Gráficos circulares: Proporción de partes dentro de un todo.
- Histogramas: Distribución de datos numéricos.
- Diagramas de dispersión: Relación entre dos variables numéricas.
- Mapas: Datos geográficos. [Image of: Ejemplos de diferentes tipos de gráficos]
Principios de Diseño para Gráficos Efectivos
- Simplicidad: Evita la sobrecarga de información.
- Claridad: Los elementos deben ser fáciles de entender.
- Coherencia: Utiliza un estilo visual consistente.
- Relevancia: Solo incluye la información necesaria.
- Estética: Un diseño atractivo puede mejorar la comprensión.
Errores Comunes en la Creación de Gráficos
- Escalas engañosas: Manipulación de las escalas para distorsionar los datos.
- Uso excesivo de efectos 3D: Puede dificultar la lectura.
- Colores poco contrastantes: Dificulta la distinción entre elementos.
- Legendas confusas: Deben ser claras y concisas.
Herramientas para Crear Gráficos
- Hojas de cálculo: Excel, Google Sheets.
- Software especializado: Tableau, Power BI, R, Python.
Conclusión
La elección y el diseño adecuados de los elementos de un gráfico son fundamentales para comunicar información de manera efectiva. Al comprender los principios básicos de la visualización de datos, podemos crear gráficos que sean no solo estéticamente agradables, sino también altamente informativos.
¿Te gustaría profundizar en algún elemento en particular o explorar ejemplos más detallados?
Posibles temas a explorar en futuras unidades:
- La importancia del color en la visualización de datos
- Cómo elegir el tipo de gráfico adecuado para tus datos
- Diseño de dashboards interactivos
- Visualización de datos en tiempo real
Principios de la percepción visual
Principios de la percepción visual. Cómo el cerebro procesa la información visual.
La visualización de datos no es solo una técnica estética; es una ciencia que aprovecha la forma en que el cerebro humano procesa la información visual. Comprender estos principios fundamentales nos permitirá crear visualizaciones más efectivas y comunicar nuestras ideas de manera más clara.
¿Qué es la Percepción Visual?
- Definición: La percepción visual es el proceso mediante el cual el cerebro interpreta la información que recibe a través de los ojos.
- El papel del cerebro: El cerebro organiza, interpreta y da sentido a las imágenes que vemos.
- Factores que influyen en la percepción: Experiencias previas, cultura, contexto y expectativas personales.
Principios Básicos de la Percepción Visual
- Ley de la pregnancia (o buena forma): Tendemos a percibir las formas de la manera más simple y organizada posible. [Image of: Ejemplos de figuras ambiguas y cómo el cerebro las interpreta de forma simple]
- Ley de proximidad: Elementos cercanos se perciben como un grupo. [Image of: Puntos agrupados por proximidad]
- Ley de semejanza: Elementos similares se perciben como un grupo. [Image of: Formas similares agrupadas]
- Ley de continuidad: Tendemos a seguir líneas o curvas suaves en lugar de cambios bruscos. [Image of: Líneas que se perciben como continuas a pesar de interrupciones]
- Ley de cierre: Tendemos a completar formas incompletas. [Image of: Figuras incompletas que el cerebro completa]
- Figura-fondo: Separamos los objetos de su entorno. [Image of: Vaso de Rubin]
Aplicación de los Principios de la Percepción Visual en la Visualización de Datos
- Claridad y simplicidad: Evitar la sobrecarga visual y utilizar elementos visuales claros y concisos.
- Jerarquía visual: Guiar la atención del espectador hacia los elementos más importantes.
- Coherencia visual: Utilizar un estilo visual consistente en toda la visualización.
- Color y contraste: Utilizar el color de manera efectiva para resaltar patrones y diferencias.
- Tipografía: Seleccionar fuentes legibles y adecuadas para el contexto.
- Espacio en blanco: Utilizar el espacio en blanco para mejorar la legibilidad y reducir la fatiga visual.
Errores Comunes en la Visualización y Cómo Evitarlos
- Sobrecarga de información: Demasiados datos en una sola visualización.
- Uso incorrecto del color: Utilización de demasiados colores o colores que dificultan la distinción.
- Escalas engañosas: Manipulación de las escalas para distorsionar los datos.
- Gráficos inadecuados: Utilización de un tipo de gráfico que no es adecuado para los datos.
Ejemplos Prácticos
- Comparación de diferentes tipos de gráficos: Cómo los principios de la percepción visual afectan la interpretación de los datos.
- Análisis de visualizaciones exitosas y fallidas: Identificación de los principios aplicados y los errores cometidos.
Conclusión
Comprender los principios de la percepción visual es fundamental para crear visualizaciones efectivas. Al aplicar estos principios, podemos diseñar visualizaciones que sean no solo estéticamente agradables, sino también altamente informativas y persuasivas.
¿Te gustaría profundizar en algún principio específico o explorar ejemplos más detallados?
Posibles temas a explorar en futuras unidades:
- El papel del color en la visualización de datos
- La psicología del color y cómo afecta nuestras emociones
- La importancia de la tipografía en la visualización
- Cómo crear narrativas visuales efectivas
Introducción a la Visualización de Datos
Introducción a la Visualización de Datos
- ¿Qué es la visualización de datos? Definición y conceptos básicos.
- ¿Por qué es importante? Beneficios y aplicaciones en diversos campos.
- Historia de la visualización de datos. Evolución desde los primeros gráficos hasta las herramientas modernas.
Historia de la visualización de datos
Historia de la visualización de datos. Evolución desde los primeros gráficos hasta las herramientas modernas.
La visualización de datos no es una invención reciente. De hecho, sus raíces se remontan a miles de años atrás. A lo largo de la historia, la humanidad ha buscado formas creativas de representar información compleja de manera visual, desde las antiguas civilizaciones hasta la era digital. En esta unidad, exploraremos la evolución de la visualización de datos, desde sus inicios hasta las herramientas sofisticadas que utilizamos hoy en día.
Los Orígenes de la Visualización
- Civilizaciones antiguas:Mapas: Las primeras civilizaciones crearon mapas para representar territorios, rutas comerciales y movimientos astronómicos.
- Petroglifos y pictografías: Utilización de imágenes para transmitir información y contar historias. [Image of: Ejemplos de mapas antiguos y petroglifos]
- Edad Media:Vitrales: Representaciones visuales de historias bíblicas y eventos históricos.
- Manuscritos iluminados: Uso de ilustraciones para complementar textos. [Image of: Vitrales y manuscritos iluminados]
El Nacimiento de los Gráficos Estadísticos
- Siglo XVIII:William Playfair: Considerado el padre de los gráficos modernos, introdujo gráficos de líneas, barras y circulares para representar datos económicos. [Image of: Ejemplos de gráficos de Playfair]
- Siglo XIX:Charles Joseph Minard: Creó uno de los gráficos más famosos de la historia, representando la campaña de Napoleón en Rusia. [Image of: Mapa de la campaña de Napoleón]
La Era de la Industrialización y la Revolución de los Datos
- Siglo XIX y XX:Explosión de datos: El crecimiento de la industria y la ciencia generó una gran cantidad de datos que necesitaban ser organizados y visualizados.
- Desarrollo de nuevos tipos de gráficos: Histograma, diagrama de caja, etc.
- Segunda Guerra Mundial:Visualización para la toma de decisiones militares: Mapas, gráficos y tablas se utilizaron para planificar estrategias y analizar datos de inteligencia.
La Era Digital y la Visualización Moderna
- Informática:Hojas de cálculo: Excel revolucionó la forma en que se analizaban y visualizaban datos.
- Software especializado: Surgimiento de herramientas como Tableau, Power BI, R y Python.
- Big data:Visualización de grandes volúmenes de datos: Desafíos y oportunidades.
- Dashboards interactivos: Exploración de datos en tiempo real.
- Inteligencia artificial:Visualización automática: Herramientas que generan visualizaciones de forma automática a partir de datos.
Tendencias Futuras
- Realidad virtual y aumentada: Inmersión en los datos.
- Visualización generativa: Creación de visualizaciones artísticas y abstractas.
- Ética en la visualización: Garantizar la transparencia y evitar la manipulación de datos.
Conclusión
La visualización de datos ha evolucionado desde simples representaciones gráficas hasta herramientas sofisticadas que nos permiten explorar y comprender el mundo de una manera completamente nueva. Al conocer la historia de la visualización, podemos apreciar cómo ha moldeado nuestra forma de pensar y tomar decisiones.
¿Te gustaría profundizar en alguna etapa específica de la historia de la visualización de datos o explorar alguna herramienta en particular?
Posibles temas a explorar en futuras unidades:
- Casos de estudio: Análisis de visualizaciones icónicas a lo largo de la historia.
- Personalidades influyentes: Científicos y artistas que han contribuido al desarrollo de la visualización.
- Impacto cultural: Cómo la visualización ha influido en el arte, la literatura y el diseño.
¿Por qué es importante?
¿Por qué es importante? Beneficios y aplicaciones en diversos campos.
¿Por qué es Importante la Visualización de Datos?
- Comunicación efectiva: Permite transmitir información compleja de forma sencilla y rápida.
- Detección de patrones: Facilita la identificación de tendencias, anomalías y relaciones entre variables.
- Toma de decisiones: Ayuda a respaldar decisiones basadas en datos.
- Exploración de datos: Permite descubrir información nueva y sorprendente.
[Image of: A dashboard showing various visualizations, such as line graphs, bar charts, and maps, to provide insights into a business's performance]
Ejemplos de Visualizaciones en el Mundo Real
- Negocios: Análisis de ventas, marketing, finanzas.
- Ciencia: Exploración de datos científicos, visualización de resultados de experimentos.
- Gobierno: Visualización de datos demográficos, económicos y sociales.
- Salud: Análisis de datos médicos, seguimiento de epidemias.
[Image of: A visualization showing the spread of a disease over time and geographic location]
Conclusión
La visualización de datos es una habilidad esencial en el mundo actual, donde la información está en todas partes. Al comprender los fundamentos de esta disciplina, podrás comunicar tus ideas de manera más efectiva, tomar decisiones más informadas y descubrir conocimientos ocultos en tus datos.
¿Te gustaría profundizar en algún concepto específico o explorar ejemplos más detallados?
Posibles temas a explorar en futuras unidades:
- Herramientas de visualización de datos (Tableau, Power BI, Python, R)
- Diseño de visualizaciones interactivas
- Ética en la visualización de datos
- Tendencias futuras en visualización de datos
¿Qué es la visualización de datos?
¿Qué es la visualización de datos? Definición y conceptos básicos.
Introducción
¿Por qué vemos más allá de los números? La visualización de datos es una herramienta poderosa que nos permite transformar números fríos y complejos en historias visuales, fáciles de entender y recordar. En este módulo, exploraremos los fundamentos de esta disciplina y su importancia en el mundo actual.
[Image of: A comparison between a table of numbers and a visually appealing graph representing the same data]
¿Qué es la Visualización de Datos?
- Definición: La visualización de datos es la representación gráfica de información y datos. Utiliza elementos visuales como gráficos, diagramas, mapas y tablas para comunicar ideas de manera efectiva.
- Objetivo: El objetivo principal es facilitar la comprensión de grandes conjuntos de datos, identificar patrones, tendencias y relaciones ocultas, y comunicar hallazgos de manera clara y concisa.
Elementos Básicos de una Visualización
- Datos: La materia prima de cualquier visualización. Pueden ser numéricos, categóricos o temporales.
- Variables: Las características que se miden y representan en la visualización.
- Escalas: La forma en que se representan los valores de las variables.
- Ejes: Las líneas que definen los límites de la visualización y permiten ubicar los datos.
- Marcadores: Los elementos visuales que representan los datos, como puntos, líneas o barras.
- Leyendas: Explicaciones de los símbolos y colores utilizados en la visualización.
[Image of: A simple scatter plot with labeled axes, legend, and data points]
Tipos de Visualizaciones
- Gráficos estadísticos: Histogramas, diagramas de caja, gráficos de dispersión, etc.
- Mapas: Coropletas, mapas de puntos, mapas de flujo, etc.
- Infografías: Combinaciones de gráficos, texto e imágenes para contar historias.
- Dashboards: Interfaces interactivas que permiten explorar y analizar datos de forma dinámica.
[Image of: A collage of different types of visualizations, such as a histogram, a map, an infographic, and a dashboard]
Principios de Diseño para Visualizaciones Efectivas
- Claridad: La visualización debe ser fácil de entender a primera vista.
- Concisión: Se debe evitar la sobrecarga de información.
- Coherencia: Los elementos visuales deben estar relacionados entre sí de forma lógica.
- Estética: La visualización debe ser visualmente atractiva.
[Image of: A comparison between a cluttered and a clean visualization]
Ejemplos de Visualizaciones en el Mundo Real
- Negocios: Análisis de ventas, marketing, finanzas.
- Ciencia: Exploración de datos científicos, visualización de resultados de experimentos.
- Gobierno: Visualización de datos demográficos, económicos y sociales.
- Salud: Análisis de datos médicos, seguimiento de epidemias.
[Image of: A visualization showing the spread of a disease over time and geographic location]
Conclusión
La visualización de datos es una habilidad esencial en el mundo actual, donde la información está en todas partes. Al comprender los fundamentos de esta disciplina, podrás comunicar tus ideas de manera más efectiva, tomar decisiones más informadas y descubrir conocimientos ocultos en tus datos.
¿Te gustaría profundizar en algún concepto específico o explorar ejemplos más detallados?
Posibles temas a explorar en futuras unidades:
- Herramientas de visualización de datos (Tableau, Power BI, Python, R)
- Diseño de visualizaciones interactivas
- Ética en la visualización de datos
- Tendencias futuras en visualización de datos
Introducción al
Análisis de Datos
2. Uso Básico de Prompts en el Análisis de Datos
Actividades Prácticas Sugeridas:
Actividades Prácticas Sugeridas:
Los prompts de IA están transformando la forma en que interactuamos con los datos. Al dominar las técnicas de ingeniería de prompts, los analistas de datos pueden aprovechar el poder de los modelos de lenguaje para obtener insights más profundos y tomar decisiones más informadas.
Al realizar estas actividades, los estudiantes podrán desarrollar habilidades prácticas en el uso de prompts de IA y comprender mejor su potencial en el análisis de datos.
- Experimentar con diferentes prompts en una plataforma como ChatGPT para ver cómo afectan los resultados.
- Crear un prompt para generar un resumen de un artículo científico.
- Utilizar un prompt para generar código Python para realizar una tarea de análisis de datos.
- Diseñar un prompt para identificar sesgos en un conjunto de datos.
8. El Futuro de los Prompts en el Análisis de Datos
Automatización de tareas: Los prompts pueden automatizar muchas tareas repetitivas en el análisis de datos.
Colaboración humano-máquina: Los analistas de datos pueden trabajar junto con los modelos de lenguaje para obtener mejores resultados.
Democratización de la IA: Los prompts hacen que la IA sea más accesible para personas sin conocimientos técnicos profundos.
7. Desafíos y Consideraciones
Sesgos: Los modelos de lenguaje pueden reflejar los sesgos presentes en los datos de entrenamiento.
Hallucinaciones: Los modelos pueden generar información falsa o engañosa.
Interpretabilidad: Puede ser difícil entender cómo el modelo llega a una conclusión.
6. Herramientas y Plataformas
Modelos de lenguaje grandes: GPT-3, Jurassic-1 Jumbo, LaMDA.
Plataformas de IA conversacional: ChatGPT, Bard.
Notebooks: Jupyter Notebook, Google Colab.
5. Aplicaciones de los Prompts en el Análisis
- Exploración de datos:
- Resumir grandes conjuntos de datos.
- Identificar patrones y tendencias.
- Generar hipótesis.
- Limpieza y preparación de datos:
- Identificar y corregir errores en los datos.
- Transformar datos en formatos adecuados para el análisis.
- Modelado y predicción:
- Generar código para construir modelos de machine learning.
- Interpretar los resultados de los modelos.
- Visualización de datos:
- Generar descripciones de visualizaciones.
- Crear código para visualizar datos.
4. Técnicas de Ingeniería de Prompts
- Prompt engineering: El arte de diseñar prompts para obtener los mejores resultados de un modelo de lenguaje.
- Técnicas:
- Reformulación: Replantear el prompt de diferentes maneras para obtener diversas respuestas.
- Aumento de contexto: Agregar más información al prompt para mejorar la calidad de la respuesta.
- Cadena de pensamiento: Guiar al modelo a través de una secuencia de pasos para resolver un problema.
- Few-shot learning: Proporcionar al modelo algunos ejemplos antes de hacerle una pregunta.
3. Componentes de un Prompt Efectivo
Claridad y concisión: El prompt debe ser claro y conciso para evitar ambigüedades.
Contexto: Proporcionar contexto relevante al modelo ayuda a generar respuestas más precisas.
Instrucciones específicas: Indicar claramente qué se espera del modelo.
Ejemplos: Incluir ejemplos puede ayudar al modelo a comprender mejor la tarea.
2. ¿Qué es un Prompt?
Definición: Un prompt es una secuencia de texto que sirve como entrada para un modelo de lenguaje.
Función: Los prompts guían al modelo hacia la generación de un texto específico, ya sea una respuesta a una pregunta, una traducción, una creación de contenido o una tarea más compleja.
1. Introducción a los Prompts de IA en el Análisis
Introducción a los Prompts de IA en el Análisis de Datos
Los prompts de IA son instrucciones o preguntas específicas que se le proporcionan a un modelo de lenguaje para obtener una respuesta o realizar una tarea determinada. En el contexto del análisis de datos, los prompts se utilizan para interactuar con modelos de lenguaje grandes (LLMs) y obtener insights valiosos a partir de grandes volúmenes de información. Esta unidad explorará los fundamentos del uso de prompts de IA en el análisis de datos.
1. Fundamentos de Análisis de Datos usando Excel
Actividades prácticas sugeridas
- Crear una hoja de cálculo con datos de ventas y realizar un análisis básico para identificar los productos más vendidos, los clientes más importantes y las tendencias de ventas.
- Utilizar una tabla dinámica para analizar los datos de un censo poblacional y obtener información sobre la distribución por edad, género y nivel educativo.
- Crear un gráfico que visualice la relación entre dos variables numéricas.
- Realizar un análisis de correlación para determinar si existe una relación entre dos variables.
Al realizar estas actividades, los estudiantes consolidarán sus conocimientos y adquirirán habilidades prácticas en el análisis de datos utilizando Excel.
9. Conclusión
Excel es una herramienta versátil y accesible para realizar análisis de datos básicos. Sin embargo, es importante comprender sus limitaciones y considerar otras herramientas más especializadas cuando sea necesario. Al dominar los fundamentos del análisis de datos en Excel, se adquiere una base sólida para abordar problemas más complejos y explorar otras herramientas de análisis.
Nota: Esta unidad de contenido puede ampliarse incluyendo temas como:
- Análisis de series de tiempo: Analizar datos que se recolectan a intervalos regulares de tiempo.
- Minería de datos: Descubrir patrones y relaciones ocultas en grandes conjuntos de datos.
- Inteligencia de negocios: Utilizar los resultados del análisis para tomar decisiones informadas.
8. Limitaciones de Excel para el Análisis de Datos
Tamaño de los datos: Excel puede tener limitaciones en el manejo de grandes conjuntos de datos.
Complejidad de los análisis: Para análisis más complejos, herramientas especializadas como R o Python pueden ser más adecuadas.
7. Análisis de Datos Avanzados con Excel
Análisis de hipótesis: Utilizar herramientas como "Análisis de datos" para realizar pruebas t, ANOVA y otras pruebas estadísticas.
Regresión lineal: Modelar la relación entre variables numéricas.
6. Visualización de Datos en Excel
Gráficos: Crear diversos tipos de gráficos (barras, líneas, circulares, dispersión) para visualizar los datos.
Formatos condicionales: Aplicar formatos a las celdas en función de criterios específicos para resaltar patrones y tendencias.
5. Tablas Dinámicas: Una Potente Herramienta
- Creación de tablas dinámicas: Convertir rangos de datos en tablas dinámicas para resumir y analizar datos de forma interactiva.
- Campos de fila, columna y valores: Configurar la tabla dinámica para mostrar los datos de la forma deseada.
- Filtros y segmentación de datos: Analizar los datos desde diferentes perspectivas utilizando filtros y segmentación.
- Cálculos personalizados: Crear cálculos personalizados para obtener información más detallada.
4. Funciones Esenciales en Excel para el Análisis
- Funciones estadísticas:
- MEDIANTA: Calcula el promedio de un rango de celdas.
- MEDIANA: Encuentra el valor central de un conjunto de datos.
- MODA: Identifica el valor que aparece con mayor frecuencia.
- DESVEST: Calcula la desviación estándar de un conjunto de datos.
- VAR: Calcula la varianza de un conjunto de datos.
- Funciones lógicas:
- SI: Realiza una prueba lógica y devuelve un valor si la condición es VERDADERO, y otro si es FALSO.
- Y: Devuelve VERDADERO si todos los argumentos son VERDADERO.
- O: Devuelve VERDADERO si al menos uno de los argumentos es VERDADERO.
- Funciones de búsqueda y referencia:
- BUSCARV: Busca un valor en la primera columna de una tabla y devuelve un valor en la misma fila desde una columna especificada.
- ÍNDICE: Devuelve el valor de una celda en una ubicación especificada por un número de fila y un número de columna.
- COINCIDIR: Devuelve la posición relativa de un elemento en un rango.
3. Preparación de los Datos en Excel
Importación de datos: Aprender a importar datos de diversos formatos (CSV, Excel, bases de datos).
Limpieza de datos: Identificar y corregir errores comunes como valores faltantes, duplicados o inconsistencias.
Transformación de datos: Manipular datos para adecuarlos al análisis (agrupar, filtrar, calcular).
2. Conceptos Básicos de Análisis de Datos
Datos: Información recopilada y organizada para su análisis.
Variable: Característica o atributo que se mide en un conjunto de datos.
Observación: Una instancia individual de un conjunto de datos.
Conjunto de datos: Colección de observaciones relacionadas.
1. Introducción al análisis de datos con Excel
Introducción al Análisis de Datos con Excel
Excel, a pesar de ser una herramienta principalmente diseñada para cálculos y gestión de hojas de cálculo, ofrece un conjunto robusto de herramientas para el análisis de datos. Su interfaz intuitiva y la amplia disponibilidad lo convierten en una opción popular para quienes se inician en el mundo de la analítica.
3. Preparación y limpieza de datos
Evaluaciones
Rúbrica
Test Secuencia
5. Cierre
La preparación y limpieza de datos son pasos esenciales para garantizar la calidad y confiabilidad de los resultados del análisis de datos. Al utilizar las herramientas y técnicas adecuadas en R, los analistas de datos pueden transformar conjuntos de datos sin procesar en datos de alta calidad listos para ser analizados y obtener información valiosa.
5.1 Importancia de la calidad de los datos:
La calidad de los datos es fundamental para la validez y confiabilidad de cualquier análisis. Un conjunto de datos de baja calidad puede conducir a resultados incorrectos o engañosos.
5.2 Consideraciones éticas:
La preparación y limpieza de datos deben realizarse de manera ética, protegiendo la privacidad de los individuos y la confidencialidad de la información.
4. Buenas Prácticas para la Preparación
y Limpieza de Datos
- Documentar el proceso: Registrar las decisiones tomadas durante la preparación y limpieza de datos para facilitar la reproducibilidad y el seguimiento del proceso.
- Validar los datos: Verificar que los datos limpios sean consistentes, precisos y adecuados para el análisis.
- Utilizar herramientas de visualización: Explorar los datos visualmente para identificar posibles problemas y patrones.
- Considerar el contexto del análisis: La preparación y limpieza de datos deben realizarse teniendo en cuenta los objetivos específicos del análisis.
3. Herramientas para la Preparación
y Limpieza de Datos en R
R ofrece una amplia gama de paquetes y funciones para la preparación y limpieza de datos, incluyendo:
- Paquete
dplyr: Un paquete versátil para manipular y transformar datos de manera eficiente. - Paquete
tidyverse: Una colección de paquetes que integran herramientas para la limpieza, análisis y visualización de datos. - Paquete
data.table: Un paquete rápido y eficiente para trabajar con grandes conjuntos de datos. - Función
is.na(): Detecta valores ausentes (NA) en un vector de datos. - **Función
na.omit(): Elimina filas o columnas con valores ausentes. - **Función
impute(): Imputa valores ausentes con valores medios, medianas o utilizando métodos más sofisticados. - **Función
transform(): Transforma variables dentro de un conjunto de datos. - **Función
unique(): Identifica y elimina valores duplicados en un vector de datos.
2. Importancia de la Preparación
y Limpieza de Datos
Los datos sin procesar a menudo contienen errores, valores ausentes, inconsistencias y formatos inconsistentes que pueden afectar la calidad del análisis. La preparación y limpieza de datos implica:
- Identificar y corregir errores: Detectar y corregir errores de tipeo, entrada de datos incorrecta o valores inconsistentes.
- Manejar valores ausentes: Tratar los valores ausentes de manera adecuada, ya sea eliminándolos, imputándolos o utilizando técnicas específicas para manejarlos.
- Transformar datos: Transformar los datos a un formato adecuado para el análisis, como convertir fechas, escalar variables o normalizar datos.
- Detectar y eliminar duplicados: Identificar y eliminar registros duplicados que puedan sesgar los resultados del análisis.
- Estandarizar formatos: Estandarizar los formatos de fecha, hora, unidades de medida y otros aspectos para garantizar la coherencia en los datos.
1. Introducción a la Preparación
y Limpieza de Datos
La preparación y limpieza de datos son pasos cruciales en cualquier proyecto de análisis de datos. Un conjunto de datos de alta calidad es esencial para obtener resultados confiables y precisos en el análisis. R ofrece diversas herramientas y técnicas para preparar y limpiar datos de manera efectiva.
2. Almacenamiento y Recopilación de datos
Guía de Observación
6. Consideraciones
El almacenamiento y la recopilación de datos son aspectos fundamentales para un análisis de datos efectivo. La elección del método de almacenamiento adecuado y la implementación de buenas prácticas para la recopilación de datos garantizan la calidad, integridad y seguridad de los datos, lo que permite obtener resultados confiables y útiles para la toma de decisiones.
6.1 Consideraciones éticas:
Es importante considerar las implicaciones éticas de la recopilación de datos, como la privacidad, el consentimiento y la protección de datos personales.
6.2 Integración de datos:
En muchos casos, los datos se recopilan de diversas fuentes y deben integrarse en un formato único para su análisis. La integración de datos implica combinar, fusionar y transformar los datos para crear un conjunto de datos coherente. Este proceso puede ser complejo y requiere herramientas y técnicas especializadas, como:
- Herramientas ETL (Extracción, Transformación y Carga): automatizan el proceso de extracción de datos de diferentes fuentes, transformación de los datos según sea necesario y carga de los datos en un destino final.
- Mapas de datos: representan las relaciones entre diferentes fuentes de datos y definen cómo se deben combinar y transformar los datos.
- Herramientas de calidad de datos: identifican y corrigen errores, valores ausentes o inconsistencias en los datos.
6.3 Almacenamiento en la nube
El almacenamiento en la nube ofrece una solución flexible y escalable para almacenar grandes volúmenes de datos. Los servicios de almacenamiento en la nube como Amazon S3, Microsoft Azure Blob Storage o Google Cloud Storage permiten:
- Acceso remoto: Acceder a los datos desde cualquier lugar con conexión a internet.
- Escalabilidad: Escalar la capacidad de almacenamiento de forma elástica según las necesidades.
- Colaboración: Compartir datos con otros usuarios o equipos de forma segura.
- Análisis de datos: Realizar análisis de datos directamente en la nube utilizando herramientas y servicios integrados.
6.4 Consideraciones de seguridad
La seguridad de los datos es un aspecto crucial en el almacenamiento y la recopilación de datos. Es importante implementar medidas de seguridad para proteger los datos contra el acceso no autorizado, el uso indebido y la divulgación. Algunas medidas de seguridad recomendadas incluyen:
- Control de acceso: Limitar el acceso a los datos a usuarios autorizados mediante autenticación y autorización.
- Cifrado: Cifrar los datos en reposo y en tránsito para protegerlos contra accesos no autorizados.
- Copias de seguridad: Realizar copias de seguridad regulares de los datos para garantizar su recuperación en caso de pérdida o daño.
- Monitoreo y auditoría: Monitorear el acceso a los datos y las actividades de los usuarios para detectar anomalías o posibles amenazas.
5. Buenas prácticas para la recopilación de datos
Planificación: Definir claramente los objetivos de la recopilación de datos, las variables de interés y las fuentes de datos.
Consentimiento: Obtener el consentimiento informado de los individuos cuando sea necesario.
Precisión: Asegurar la precisión y confiabilidad de los datos recopilados.
Completitud: Minimizar los valores ausentes o inconsistentes en los datos.
Seguridad: Proteger los datos confidenciales y sensibles contra el acceso no autorizado.
Estandarización: Implementar estándares para el formato y la organización de los datos.
Documentación: Documentar el proceso de recopilación de datos y las fuentes de datos utilizadas.
4. Herramientas para la captura de datos
4.1 Web scraping:
- Extraer datos de sitios web utilizando herramientas como Scrapy, Beautiful Soup o Octoparse.
4.2 APIs:
- Acceder a datos de aplicaciones web y servicios en línea mediante APIs como las de redes sociales, plataformas de comercio electrónico o servicios financieros.
4.3 Encuestas:
- Recopilar datos de individuos o grupos mediante encuestas online o en papel utilizando herramientas como SurveyMonkey, Google Forms o LimeSurvey.
4.4 Entrevistas:
- Obtener información en profundidad de individuos mediante entrevistas estructuradas o no estructuradas.
4.5 Experimentos:
- Recopilar datos bajo condiciones controladas utilizando herramientas de experimentación como LabVIEW o jsPsych.
4.6 Sensores:
- Recopilar datos de dispositivos físicos como sensores de temperatura, presión o movimiento utilizando plataformas como Arduino o Raspberry Pi.
3. Factores a considerar para la selección
del método de almacenamiento
Volumen de datos: La cantidad de datos a almacenar determinará la capacidad y el rendimiento requeridos del sistema de almacenamiento.
Estructura de datos: La estructura de los datos (estructurados, no estructurados, semiestructurados) influirá en la elección del método de almacenamiento adecuado.
Patrones de acceso: Los patrones de acceso a los datos (consultas analíticas complejas, acceso en tiempo real, análisis exploratorio) determinarán el rendimiento y la funcionalidad requerida del sistema de almacenamiento.
Costo: El costo de las licencias, el hardware y el mantenimiento de los diferentes métodos de almacenamiento debe ser considerado.
2. Métodos de almacenamiento de datos
2.1 Bases de datos relacionales:
- Almacenan datos estructurados en tablas con relaciones definidas entre ellas.
- Adecuadas para grandes volúmenes de datos transaccionales y análisis estructurados.
- Ejemplos: MySQL, PostgreSQL, Oracle.
2.2 Almacenes de datos:
- Diseñados para almacenar grandes volúmenes de datos históricos y agregados para su análisis.
- Optimizados para consultas analíticas complejas y visualización de datos.
- Ejemplos: Amazon Redshift, Microsoft Azure Synapse Analytics, Google BigQuery.
2.3 Data lakes:
- Almacenan datos sin procesar en su formato nativo, independientemente de su estructura o formato.
- Permiten un análisis flexible y exploratorio de diversos tipos de datos.
- Ejemplos: Amazon S3, Microsoft Azure Data Lake Storage, Google Cloud Storage.
2.4 NoSQL:
- Almacenan datos no estructurados o semiestructurados en formatos flexibles, como documentos, JSON o gráficos.
- Adecuados para datos que no encajan bien en el modelo relacional tradicional.
- Ejemplos: MongoDB, Cassandra, CouchDB.
1. Introducción al almacenamiento
y recopilación de datos
El almacenamiento y la recopilación de datos son etapas cruciales en el proceso de análisis de datos. La elección del método de almacenamiento adecuado depende del volumen, la estructura y el uso previsto de los datos. La recopilación de datos implica la extracción de datos de diversas fuentes y su organización para su análisis.
1. Fuentes y tipos de datos
Listas de Cotejo
6. Cierre
La selección adecuada de fuentes y tipos de datos es fundamental para el éxito de cualquier proyecto de análisis de datos. Al considerar la relevancia, precisión, completitud, actualidad, legalidad y ética de los datos, los analistas de datos pueden garantizar la calidad de sus análisis y obtener resultados confiables y útiles.
6.1 Importancia de la limpieza de datos:
Independientemente de la fuente, los datos a menudo contienen errores, valores ausentes o inconsistencias. La limpieza de datos es un paso crucial para preparar los datos para el análisis y garantizar su calidad.
6.2 Integración de datos:
En muchos casos, los datos se recopilan de diversas fuentes y deben integrarse en un formato único para su análisis. La integración de datos implica combinar, fusionar y transformar los datos para crear un conjunto de datos coherente.
5. Herramientas para la recopilación de datos
Web scraping: para extraer datos de sitios web.
APIs: para acceder a datos de aplicaciones web y servicios en línea.
Encuestas: para recopilar datos de individuos o grupos.
Entrevistas: para obtener información en profundidad de individuos.
Experimentos: para recopilar datos bajo condiciones controladas.
Sensores: para recopilar datos de dispositivos físicos.
4. Consideraciones para la selección
de fuentes y tipos de datos
Relevancia: Los datos deben ser relevantes para los objetivos del análisis y responder a las preguntas de investigación.
Precisión: Los datos deben ser precisos y confiables para garantizar la calidad de los resultados del análisis.
Completitud: Los datos deben estar completos y no contener valores ausentes o inconsistencias.
Actualidad: Los datos deben estar actualizados y reflejar la situación actual.
Legalidad y ética: Se deben considerar las leyes y regulaciones relacionadas con la recopilación y uso de datos, así como los principios éticos de la investigación.
3. Tipos de datos
3.1 Datos cuantitativos:
- Se pueden medir en números y representar valores numéricos.
- Ejemplos: edad, ingresos, temperatura, ventas, calificaciones.
3.2 Datos cualitativos:
- No se pueden medir en números y representan características o atributos no numéricos.
- Ejemplos: opiniones, preferencias, emociones, comentarios, categorías.
3.3 Datos estructurados:
- Están organizados en un formato definido, como tablas de bases de datos o archivos CSV.
- Fáciles de almacenar, procesar y analizar con herramientas informáticas.
3.4 Datos no estructurados:
- No tienen un formato definido y pueden incluir texto libre, imágenes, audio o video.
- Requiere técnicas de procesamiento de lenguaje natural, análisis de imágenes o análisis de audio/video para su análisis.
2. Tipos de fuentes de datos
2.1 Fuentes de datos internas:
- Bases de datos: almacenan datos estructurados y organizados, como transacciones de ventas, registros de clientes o datos financieros.
- Sistemas transaccionales: registran actividades y eventos en tiempo real, como sistemas de punto de venta o registros de acceso a redes.
- Datos de sensores: recopilan datos de dispositivos físicos, como sensores de temperatura, presión o movimiento.
2.2 Fuentes de datos externas:
- Datos web: se pueden extraer de sitios web, redes sociales y otras plataformas online.
- Datos públicos: están disponibles gratuitamente en portales gubernamentales, organizaciones internacionales o repositorios de datos abiertos.
- Datos de terceros: se pueden comprar a proveedores de datos especializados o a través de plataformas de intercambio de datos.
1. Introducción a las fuentes y tipos de datos
El análisis de datos comienza con la recopilación de datos de diversas fuentes. La elección de la fuente de datos correcta es crucial para garantizar la calidad, confiabilidad y relevancia de los datos para los objetivos del análisis.
3. Proceso general del análisis de datos
Flashcards y Cuestionarios
4. Cierre
El proceso de análisis de datos con R proporciona una metodología sistemática para transformar datos sin procesar en información útil y significativa. Al seguir las buenas prácticas y utilizar las herramientas adecuadas, los analistas de datos pueden obtener conocimientos valiosos de los datos y contribuir a la toma de decisiones informadas en diversos campos.
4.1 Importancia de la comunicación:
La comunicación efectiva de los resultados del análisis de datos es crucial para garantizar que sean utilizados por las partes interesadas y para generar un impacto positivo.
4.2 Aprendizaje continuo:
El campo del análisis de datos está en constante evolución, por lo que es importante que los analistas de datos se mantengan actualizados sobre las últimas técnicas y herramientas.
3. Buenas prácticas para el análisis de datos con R
Documentar el proceso de análisis: Es importante documentar cada paso del proceso de análisis de datos, incluyendo la fuente de datos, la metodología utilizada y los resultados obtenidos.
Reproducibilidad: El análisis de datos debe ser reproducible, lo que significa que otros investigadores deberían poder obtener los mismos resultados utilizando el mismo código y datos.
Validación de modelos: Los modelos de análisis de datos deben validarse cuidadosamente antes de utilizarse para tomar decisiones.
Interpretabilidad de los modelos: Es importante comprender cómo funcionan los modelos de análisis de datos para poder interpretar sus resultados y confiar en sus predicciones.
2. Herramientas para el análisis de datos con R
R es un lenguaje de programación y entorno de software ampliamente utilizado para el análisis de datos. Ofrece una amplia gama de herramientas y paquetes especializados para cada etapa del proceso de análisis de datos, incluyendo:
- Recolección de datos: paquetes para leer datos de diversas fuentes, como bases de datos, archivos CSV y APIs.
- Limpieza y preparación de datos: paquetes para identificar y corregir errores, valores ausentes y inconsistencias en los datos.
- Exploración y análisis descriptivo: paquetes para crear visualizaciones de datos, calcular estadísticas descriptivas y resumir los datos.
- Modelado y análisis predictivo: paquetes para desarrollar y ajustar modelos estadísticos y de aprendizaje automático, como modelos de regresión, clasificación y series temporales.
- Comunicación y presentación de resultados: paquetes para crear visualizaciones de datos de alta calidad, generar informes y presentaciones.
1. Introducción al proceso de análisis de datos
El análisis de datos implica un proceso sistemático para transformar datos sin procesar en información útil y significativa. Este proceso generalmente se divide en las siguientes etapas:
1.1 Definición de objetivos y preguntas:
- Es crucial establecer claramente los objetivos del análisis de datos y las preguntas que se buscan responder.
- Los objetivos y las preguntas deben ser específicos, medibles, alcanzables, relevantes y con un plazo determinado (SMART).
1.2 Recolección de datos:
- Los datos se pueden recopilar de diversas fuentes, como bases de datos, encuestas, experimentos, sensores y redes sociales.
- Es importante garantizar que los datos sean precisos, completos, confiables y relevantes para los objetivos del análisis.
1.3 Limpieza y preparación de datos:
- Los datos sin procesar a menudo contienen errores, valores ausentes o inconsistencias.
- La limpieza de datos implica identificar y corregir estos problemas para garantizar la calidad de los datos.
1.4 Exploración y análisis descriptivo:
- Esta etapa consiste en explorar los datos para comprender su distribución, tendencias, patrones y relaciones.
- Se utilizan técnicas estadísticas y visualizaciones de datos para resumir y describir los datos.
1.5 Modelado y análisis predictivo:
- Se desarrollan modelos estadísticos o de aprendizaje automático para predecir resultados o tendencias futuras.
- Los modelos se evalúan en función de su precisión y capacidad para generalizar a nuevos datos.
1.6 Comunicación y presentación de resultados:
- Los hallazgos del análisis de datos se comunican de manera efectiva a las partes interesadas, utilizando visualizaciones, informes y presentaciones claras y concisas.
- Es importante comunicar los resultados de manera que sean relevantes para la audiencia y que respalden la toma de decisiones informadas.
2. Normatividad y Ética
Rúbrica de Sustentación y Cuestionarios
6. Conclusión
El análisis de datos es una herramienta poderosa que puede generar beneficios significativos para la sociedad. Sin embargo, es crucial utilizarla de manera responsable y ética, respetando los derechos individuales y la privacidad. La normatividad y la ética brindan un marco para el manejo responsable de los datos en el análisis de datos con R, asegurando que esta herramienta se utilice para el bien y no para el daño.
5. Recursos para el manejo ético de
datos en el análisis de datos con R
5.1 Importancia de la colaboración:
Es importante que los profesionales de datos, los desarrolladores de software, los responsables políticos y el público en general colaboren para desarrollar e implementar prácticas de análisis de datos éticas y responsables.
5.2 El futuro del análisis de datos:
A medida que la tecnología de análisis de datos continúa evolucionando, es fundamental que los principios éticos y legales se mantengan a la vanguardia. Es necesario un compromiso continuo para garantizar que el análisis de datos se utilice de manera responsable y beneficiosa para todos.
Al seguir las buenas prácticas descritas en este documento, los profesionales de análisis de datos pueden contribuir a un futuro en el que el análisis de datos se utilice para generar conocimientos valiosos, mejorar la toma de decisiones y crear un mundo más justo y equitativo.
5.3 Algunos enlaces de referencias de normatividad:
Comisión Nacional de Protección de Datos Personales de Colombia: https://www.minambiente.gov.co/politica-de-proteccion-de-datos-personales/
Reglamento General de Protección de Datos (RGPD): https://gdpr-info.eu/
Red Española de Protección de Datos: https://www.aepd.es/
AAI Guide on AI Ethics: https://aaai.org/about-aaai/ethics-and-diversity/
4. Buenas prácticas para el manejo ético
de datos en el análisis de datos con R
4.1 Obtención del consentimiento informado:
- Obtener el consentimiento libre e informado de los individuos antes de recopilar sus datos personales.
- Informar a los individuos sobre cómo se utilizarán sus datos, quién tendrá acceso a ellos y sus derechos con respecto a sus datos.
4.2 Minimización de datos:
- Recopilar solo la cantidad mínima de datos necesaria para el propósito específico del análisis.
- Evitar la recopilación de datos innecesarios o sensibles.
4.3 Seguridad de los datos:
- Implementar medidas de seguridad adecuadas para proteger los datos contra el acceso no autorizado, el uso indebido y la divulgación.
- Usar técnicas de cifrado y control de acceso para proteger los datos confidenciales.
4.4 Documentación y auditoría:
- Documentar las prácticas de manejo de datos,
4.5 Evaluación de impacto:
- Evaluar el impacto potencial del análisis de datos en la privacidad, la seguridad y otros derechos individuales.
- Tomar medidas para mitigar los riesgos potenciales.
4.6 Uso responsable de la inteligencia artificial:
- Al utilizar técnicas de inteligencia artificial en el análisis de datos, considerar los principios éticos y las directrices relevantes.
- Evitar el uso de la inteligencia artificial para fines discriminatorios o dañinos.
4.7 Capacitación y sensibilización:
- Capacitar a los profesionales de análisis de datos sobre los principios éticos y legales del manejo de datos.
- Sensibilizar a los usuarios sobre los riesgos y beneficios del análisis de datos.
3. Consideraciones éticas en el desarrollo
de modelos de análisis de datos
3.1 Sesgo y discriminación:
- Los modelos de análisis de datos pueden reflejar y amplificar los sesgos existentes en los datos utilizados para entrenarlos.
- Es crucial evaluar y mitigar los sesgos en los modelos para evitar la discriminación algorítmica.
3.2 Transparencia e interpretabilidad:
- Los modelos de análisis de datos, especialmente los modelos de aprendizaje automático complejos, pueden ser difíciles de interpretar.
- Es importante desarrollar modelos transparentes y explicables para que los usuarios comprendan cómo funcionan y puedan tomar decisiones informadas.
3.3 Equidad y justicia:
- Los modelos de análisis de datos deben utilizarse de manera equitativa y justa para todos los individuos.
- Es necesario evitar el uso de modelos que puedan exacerbar las desigualdades sociales o discriminar a grupos específicos.
2. Normatividad relevante para el análisis de datos
2.1 Leyes de protección de datos:
- Reglamento General de Protección de Datos (RGPD) de la Unión Europea: establece un marco legal para la protección de datos personales en la Unión Europea.
- Ley de Protección de Datos Personales de Colombia: regula la recolección, tratamiento y circulación de datos personales en Colombia.
- Ley Sarbanes-Oxley de Estados Unidos: establece requisitos para el control interno y la presentación de informes financieros, incluyendo la protección de datos.
2.2 Otras regulaciones relevantes:
- Leyes de privacidad de la información: protegen la información personal en diversos sectores, como la atención médica y los servicios financieros.
- Leyes de propiedad intelectual: protegen los derechos de autor y otros derechos de propiedad intelectual sobre los datos.
- Leyes de competencia: prohíben prácticas anticompetitivas, como el uso indebido de datos para obtener una ventaja injusta.
1. Introducción a la normatividad y
ética en el análisis de datos
1.1 ¿Por qué son importantes la normatividad y la ética en el análisis de datos?
El análisis de datos implica la recopilación, el almacenamiento y el uso de información personal y confidencial. Es crucial garantizar que estos datos se manejen de manera responsable y ética, respetando los derechos individuales y la privacidad. La normatividad y la ética brindan un marco para el manejo responsable de los datos, asegurando:
- Protección de la privacidad: los individuos tienen derecho a controlar cómo se recopilan, utilizan y divulgan sus datos personales.
- Prevención de daños: el uso indebido de los datos puede causar daños a las personas, como discriminación, fraude o robo de identidad.
- Equidad y justicia: los algoritmos y modelos de análisis de datos deben ser justos y no discriminatorios.
- Transparencia: las personas deben tener derecho a saber cómo se utilizan sus datos y quién tiene acceso a ellos.
1.2 Principios éticos clave en el análisis de datos:
- Responsabilidad: las organizaciones que recopilan y utilizan datos son responsables de su manejo ético.
- Transparencia: las personas deben tener información clara y accesible sobre cómo se recopilan, utilizan y divulgan sus datos.
- Propósito y limitación: los datos deben recopilarse y utilizarse solo para los propósitos específicos y claramente definidos.
- Precisión y calidad: los datos deben ser precisos, completos y actualizados.
- Seguridad: los datos deben protegerse contra el acceso no autorizado, el uso indebido y la divulgación.
- No discriminación: los datos no deben utilizarse para discriminar a individuos o grupos.
- Rendición de cuentas: las organizaciones deben ser responsables de sus prácticas de manejo de datos.
Para Consulta (Superintendencia de Industria y Comercio SIC)
-Documento Autorización Tratamiento de Datos Personales
.-Política de tratamiento de Datos Personales
-Política de seguridad de la Informacon
1. Conceptos Básicos
Quiz
Conclusión
En resumen, el análisis de datos es una herramienta poderosa que nos permite transformar datos sin procesar en información valiosa para tomar decisiones informadas y mejorar diversos aspectos del mundo real. R es un lenguaje de programación y entorno de software ampliamente utilizado para el análisis de datos, debido a su flexibilidad, potencia y amplia gama de paquetes especializados.
3. Relación del análisis de datos con el mundo real
El análisis de datos tiene un impacto significativo en diversos aspectos del mundo real, incluyendo:
- Negocios: las empresas utilizan el análisis de datos para mejorar sus operaciones, tomar decisiones estratégicas, aumentar las ventas y optimizar sus campañas de marketing.
- Finanzas: las instituciones financieras utilizan el análisis de datos para evaluar riesgos, detectar fraudes, gestionar inversiones y desarrollar nuevos productos financieros.
- Ciencia: los científicos utilizan el análisis de datos para analizar experimentos, identificar patrones en la naturaleza y desarrollar nuevos modelos teóricos.
- Gobierno: los gobiernos utilizan el análisis de datos para comprender mejor a sus ciudadanos, optimizar la prestación de servicios públicos y formular políticas públicas efectivas.
- Salud: los profesionales de la salud utilizan el análisis de datos para diagnosticar enfermedades, predecir resultados de tratamientos y mejorar la calidad de la atención médica.
2. Conceptos básicos del análisis de datos
2.1 Tipos de datos
- Datos cuantitativos: se pueden medir en números, como la edad, el ingreso o la temperatura.
- Datos cualitativos: no se pueden medir en números, como las opiniones, las preferencias o las emociones.
2.2 Variables
- Variables independientes: son las variables que se manipulan o cambian en un experimento.
- Variables dependientes: son las variables que se miden y se ven afectadas por las variables independientes.
2.3 Medidas estadísticas
- Medidas de tendencia central: como la media, la mediana y la moda, que resumen el valor "típico" de una variable.
- Medidas de dispersión: como la varianza y el desvío estándar, que indican la variabilidad de los datos alrededor de la media.
2.4 Asociación y correlación
- Asociación: describe la relación entre dos variables, sin especificar causa y efecto.
- Correlación: mide la fuerza y la dirección de la asociación entre dos variables.
1. Introducción al análisis de datos
1.1 ¿Qué es el análisis de datos?
El análisis de datos es el proceso de extraer información significativa de conjuntos de datos sin procesar. Implica la limpieza, manipulación, exploración, modelado y visualización de datos para descubrir patrones, tendencias y relaciones que puedan ser útiles para la toma de decisiones.
1.2 ¿Por qué es importante el análisis de datos?
El análisis de datos es crucial en el mundo actual, donde la información es abundante y compleja. Nos permite:
- Obtener conocimientos sobre el comportamiento de clientes, mercados, operaciones y otros aspectos del mundo real.
- Tomar decisiones informadas basadas en evidencia, no en intuición o suposiciones.
- Mejorar la eficiencia y la productividad en diversos sectores.
- Identificar nuevas oportunidades de negocio y crecimiento.
- Reducir riesgos y anticipar problemas potenciales.
1.3 Ejemplos de aplicaciones del análisis de datos en el mundo real:
- Análisis de ventas: para comprender las preferencias de los clientes, identificar productos populares y optimizar las estrategias de marketing.
- Análisis financiero: para evaluar riesgos crediticios, detectar fraudes y optimizar las inversiones.
- Análisis de atención médica: para diagnosticar enfermedades, predecir resultados de tratamientos y mejorar la calidad de la atención.
- Análisis de recursos humanos: para identificar empleados con alto potencial, optimizar la capacitación y reducir la rotación de personal.
- Análisis de redes sociales: para comprender el sentimiento del público, identificar tendencias y mejorar la imagen de marca.
Contenidos Revisados y No Contemplados
X. Fundamentos de Lenguaje R
Mapa
5. Conclusión
El lenguaje R ofrece un conjunto poderoso de herramientas y algoritmos para el análisis de datos. Al comprender los fundamentos del lenguaje R y familiarizarse con los diferentes tipos de algoritmos disponibles, los analistas de datos pueden abordar una amplia gama de problemas y obtener información valiosa a partir de los datos.
5.1 Importancia de la práctica:
La práctica regular es fundamental para dominar R y sus algoritmos. Existen numerosos conjuntos de datos y desafíos disponibles en línea para practicar habilidades de análisis de datos con R.
5.2 Aplicaciones del análisis de datos con R:
El análisis de datos con R se utiliza en una amplia gama de campos, incluyendo finanzas, marketing, medicina, ciencias sociales, medio ambiente y muchos más.
4. Recursos para aprender algoritmos y R
Existen numerosos recursos disponibles para aprender algoritmos y R, incluyendo:
- Documentación oficial de R: https://www.r-project.org/other-docs.html
- Libros y tutoriales: Una gran cantidad de libros y tutoriales están disponibles en línea y en bibliotecas, como "The R Language" de Peter Dalgaard o "Hands-On Machine Learning with R" de Aurélien Géron.
- Cursos online: Plataformas como Coursera, edX y Udemy ofrecen cursos online sobre R y análisis de datos.
- Comunidades en línea: Existen comunidades en línea activas, como el subreddit r/Rlanguage o el foro de Stack Overflow para R, donde puedes encontrar ayuda y colaborar con otros usuarios de R.
3. Fundamentos del lenguaje R
Para comprender y utilizar los algoritmos de R de manera efectiva, es esencial tener una base sólida en los fundamentos del lenguaje R. Esto incluye:
- Sintaxis básica: Comprender la estructura y las reglas del lenguaje R, incluyendo la definición de variables, la creación de vectores y matrices, y el uso de operadores y funciones.
- Estructuras de control: Utilizar estructuras de control como
if, else y for para controlar el flujo del programa. - Funciones: Crear y utilizar funciones personalizadas para realizar tareas específicas.
- Manejo de datos: Importar, limpiar, transformar y analizar datos utilizando paquetes de R como
dplyr, tidyverse y data.table. - Visualización de datos: Crear gráficos y visualizaciones de datos atractivas e informativas utilizando paquetes de R como
ggplot2, plotly y lattice.
2. Tipos de algoritmos en R
R ofrece una amplia variedad de algoritmos para diferentes tareas de análisis de datos. Algunos de los tipos de algoritmos más comunes incluyen:
- Algoritmos de regresión: Utilizados para modelar la relación entre una variable dependiente y una o más variables independientes.
- Algoritmos de clasificación: Utilizados para clasificar datos en categorías predefinidas.
- Algoritmos de agrupamiento: Utilizados para agrupar datos en clusters con características similares.
- Algoritmos de reducción de dimensionalidad: Utilizados para reducir la cantidad de variables en un conjunto de datos sin perder información significativa.
- Algoritmos de minería de datos: Utilizados para extraer patrones y conocimientos ocultos de grandes conjuntos de datos.
1. Introducción a los algoritmos y el lenguaje R
El lenguaje R proporciona un entorno poderoso para el análisis de datos, ofreciendo una amplia gama de algoritmos y herramientas para diversas tareas, incluyendo:
- Análisis descriptivo: Resumir y describir las características de los datos.
- Análisis exploratorio de datos (EDA): Explorar y visualizar los datos para identificar patrones, tendencias y anomalías.
- Modelado estadístico: Desarrollar modelos estadísticos para comprender las relaciones entre variables y hacer predicciones.
- Aprendizaje automático: Entrenar modelos de aprendizaje automático para realizar tareas como clasificación, regresión y agrupamiento.
- Visualización de datos: Crear visualizaciones de datos atractivas e informativas para comunicar los resultados del análisis.
7. Algoritmos Básicos con Pseudocódigo (PseInt)
Aplicación
8. Conclusión
PseInt es una herramienta valiosa para aprender a programar y desarrollar algoritmos de manera clara y estructurada. Al comprender los conceptos básicos de tipos de datos, variables, operadores e instrucciones de control de flujo, podemos comenzar a crear algoritmos más complejos y resolver problemas de programación de manera efectiva.
7. Ejemplo de Algoritmo: Calcular
el Promedio de dos Números
Proceso PromedioDosNumeros
Descripción: Calcula el promedio de dos números enteros.
// Declaración de variables
Entero numero1, numero2, promedio;
// Ingreso de datos
Escribir "Ingrese el primer número: ";
Leer numero1;
Escribir "Ingrese el segundo número: ";
Leer numero2;
// Cálculo del promedio
promedio = (numero1 + numero2) / 2;
// Mostrar el resultado
Escribir "El promedio de los números es: ", promedio;
FinProceso
En este ejemplo, el algoritmo solicita al usuario dos números enteros, calcula su promedio y muestra el resultado final.
6. Instrucciones de Control de Flujo en PseInt
Las instrucciones de control de flujo permiten modificar el orden de ejecución de las instrucciones en un algoritmo según ciertas condiciones. Algunas instrucciones comunes incluyen:
- Si (IF): Ejecuta un conjunto de instrucciones si se cumple una condición específica.
- Sino (ELSE): Ejecuta un conjunto de instrucciones alternativo si la condición del
SI no se cumple. - Mientras que (WHILE): Repite un conjunto de instrucciones mientras se cumpla una condición específica.
- Para (FOR): Repite un conjunto de instrucciones un número determinado de veces.
5. Operadores en PseInt
Los operadores permiten realizar operaciones matemáticas, lógicas y de comparación entre datos. Algunos operadores comunes en PseInt incluyen:
- Operadores aritméticos: Suma (+), resta (-), multiplicación (*), división (/), potencia (^).
- Operadores lógicos: AND (&&), OR (||), NOT (!).
- Operadores de comparación: Igual que (==), diferente que (!=), mayor que (>), menor que (<), mayor o igual que (>=), menor o igual que (<=).
4. Variables en PseInt
Las variables son elementos que almacenan datos durante la ejecución de un algoritmo. Para declarar una variable en PseInt se utiliza la siguiente sintaxis:
TipoVariable NombreVariable;
Donde:
TipoVariable indica el tipo de dato que almacenará la variable (Entero, Real, Cadena, Booleano).NombreVariable es el identificador único que se asigna a la variable.
3. Tipos de Datos en PseInt
PseInt maneja diferentes tipos de datos para almacenar información:
- Entero: Números enteros positivos o negativos, como 1, -5, 100.
- Real: Números decimales, como 3.14, -2.5, 10.25.
- Cadena: Secuencias de caracteres, como "Hola", "Mundo", "Programación".
- Booleano: Valores lógicos que pueden ser Verdadero o Falso.
2. Estructura Básica de un Algoritmo en PseInt
Un algoritmo en PseInt se compone de las siguientes partes:
- Proceso: Se inicia con la palabra
Proceso seguida del nombre del algoritmo. - Descripción: Se incluye una breve descripción del propósito del algoritmo.
- Cuerpo del Algoritmo: Aquí se detallan las instrucciones paso a paso que conforman el algoritmo. Cada instrucción termina con punto y coma.
- FinProceso: Se finaliza con la palabra
FinProceso para indicar el término del algoritmo.
1. Introducción a la Programación
con Algoritmos y PseInt
La programación es la base fundamental para el desarrollo de software y aplicaciones. Implica la creación de instrucciones detalladas que le indican a una computadora cómo realizar una tarea específica. Los algoritmos son la representación paso a paso de un proceso para resolver un problema o lograr un objetivo.
PseInt (Pseudo Algoritmo) es una herramienta de gran utilidad para aprender a programar y desarrollar algoritmos. Permite expresar algoritmos de una manera clara, lógica y estructurada, utilizando un lenguaje similar al español.
En esta unidad de contenido, exploraremos algunos algoritmos básicos en programación utilizando PseInt, sentando las bases para comprender y desarrollar programas más complejos.
Herramientas
de Producción
H5P
Revisiones
y turoriales
Imágenes
Video
CCommons




