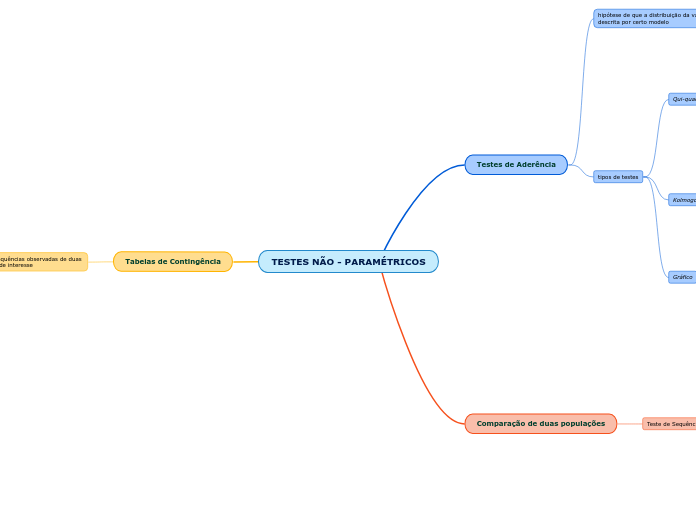
TESTES NÃO - PARAMÉTRICOS
Testes de Aderência
hipótese de que a distribuição da variável seja
descrita por certo modelo
boa ou má aderência dos dados ao modelo hipotético
tipos de testes
Qui-quadrado (X²)
X² = Σ^k [(Oi² / Ei ] - n
Oi = frequência observada
Ei = frequência esperada
n = número de elementos da amostra
k = número de valores considerados
se Ei ≥ 5 e modelo testado for verdadeiro
estatística de teste X²v com v = k - 1 -m
k = número de parcelas somadas
m = número de parâmetros estimados
Ei = n*pi
n = nº de elementos amostra
pi = probabilidade de se obter um valor da variável na classe
teste unilateral
se X² > X²crítico
hipótese H0 rejeitada
Kolmogorov - Smimov
variável de teste (d) é a maior diferença observada entre função ditribuição
acumulada do modelo (FDA) e a da amostra
FDA = F(x) = P (X ≥ x)
FDA amostra = gráfico de frequências relativas acumuladas = G(x)
comparação d d com valor crítico tabelado
d > valor crítico
rejeita H0
Gráfico
processo simplificado e aproximado
pouca exigência de rigor
papel de probabilidade normal
uma das escalas dividas conforme os percentis de diastribuição normal e a outra linear
se hipótese de normalidade for verdadeira
gráfico = reta
Comparação de duas populações
Teste de Sequências
série de observações sim/não
n1 = obervações de um tipo
n2 = observações de outro tipo
sequência (u) = conjunto de observações consecutivas de mesmo tipo
analisar se sequências ocorrem ou não ao acaso
hipótese verdadeira: sequências são aleatórias
número número de sequências não pode ser nem
muito grande nem muito pequeno
u crítico tabelado
se n1 ≥ 10 e n2 ≥ 10
distribuição de probabilidade de u aproximada pela normal
média (u) = [(2*n1*n2) / (n1 + n2)] + 1
desvio padrão (u) = {[2*n1*n2(2*n1*n2 - n1 - n2)] / [(n1 + n2)² * (n1 + n2 -1)]}^1/2
hipótese de aleatoriadade z = (u - média (u)) / desvio padrão (u)
comparação de populações
ordena-se o conjunto total de valores das duas amostras
testa aleatoriedade das sequências formadas or valores da mesma amostra
se número de sequências for baixo
rejeição da identidade entre populações
Tabelas de Contingência
representação tabular daas frequências observadas de duas
ou mais variáveis qualitativas de interesse
H0: variáveis independentes
H1: variáveis não independentes
usar teste X²
Eij = n * pij
pij = probabilidade de ocorrer observação na célula considerada (pi * pj)
pi = probabilidade marginal linha i
pj = probabilidade marginal coluna j
frequências esperadas = (total da linha * total da coluna) / frequência total
probabilidade marginais estimada atavés das frequências relativas