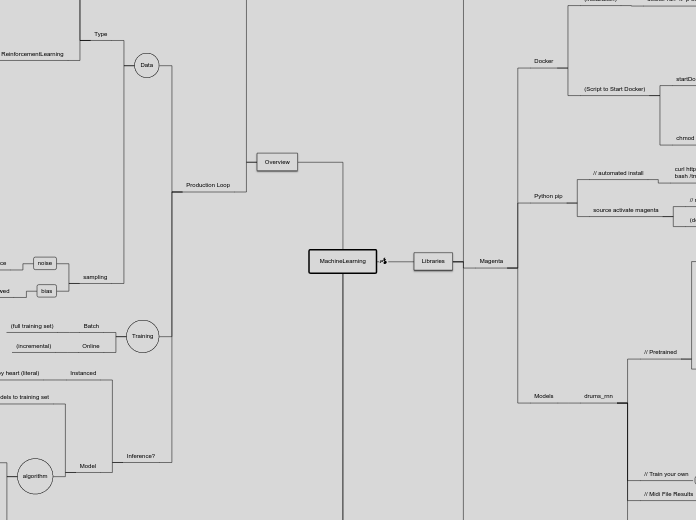
MachineLearning
Libraries
TensorFlow
Magenta
Docker
(installation)
docker run -it -p 6006:6006 -v /tmp/magenta:/magenta-data tensorflow/magenta
This will download tensorflow and will take a few minutes (~ 8 minutes)
docker pull tensorflow/magenta
// update the image to the latest version
(Script to Start Docker)
startDocker.sh
#! /bin/bash
docker run -it -p 8888:8888 gcr.io/tensorflow/tensorflow
Make a note of the URL that is given.
chmod +x startDocker.sh
// Make your script executable:
Python pip
// automated install
curl https://raw.githubusercontent.com/tensorflow/magenta/master/magenta/tools/magenta-install.sh > /tmp/magenta-install.sh
bash /tmp/magenta-install.sh
source activate magenta
// run to use Magenta every time you open a new terminal window
(deactivate)
Models
drums_rnn
// Pretrained
drum_kit.mag
// Generate a drum track
BUNDLE_PATH=<absolute path of .mag file>
CONFIG=<one of 'one_drum' or 'drum_kit', matching the bundle>
(cmd)
drums_rnn_generate \
--config=${CONFIG} \
--bundle_file=${BUNDLE_PATH} \
--output_dir=/tmp/drums_rnn/generated \
--num_outputs=10 \
--num_steps=128 \
--primer_drums="[(36,)]"
// Train your own
// Midi File Results
drums_rnn/generated
...
2017-05-28_145521_01.mid
// Play Midi
brew install timidity;
timidity yourfile.mid
Jupyter
Overview
Definition
is
machines improving at a a task learning from data
not
explicitly coded rules
Production Loop
Data
Type
Supervised
NonSupervised
ReinforcementLearning
Creating agents that maximize rewards in an environment over time
Agent learn by trial and error
Not explicitly given "right" answer
Supervision via rewards
Can't loss function/gradient descent solution
Must balance
Exploring the environment
bias
When agent remains in the same region of an environment and all it's learning are localized
Buffer past experiences further back than immediate experience
Looking for new ways to get reward
Exploiting sources of rewards it already knows
Examples
Music Personalization
reward
+
listens to
song
++
ad
-
skips
song
ad
--
closes app/leaves
Marketing
reward
+
Estimated revenue from campaign
-
Cost of Mailing campaign
Product Delivery
Delivery Fleet Management
reward
+
delivered on time
-
late delivery
sampling
noise
nonrepresntative data as a result of chance
not enough data
bias
non representative data because sampling method is flawed
Training
Batch
(full training set)
Online
(incremental)
Inference?
Instanced
Learns examples by heart (literal)
Generalizes by interpolating new instance to existing ones
Model
Tunes parameters and fits models to training set
Presumably the resulting model generalizes to the production set
algorithm
overfit
too complex
regularization
// reduce model risk of overfitting
// contstraining
// simplifying
hyper parameters
// parameter of training algorithm not training data
// must be set prior to training
// stays constant during training
underfit
too simple
concepts
Key
Components
Education
stats
Logistic regression
y^
(w^t)x + b
In statistics, logistic regression, or logit regression, or logit model[1] is a regression model where the dependent variable (DV) is categorical
binary dependent variable
output = 0 or 1
sigmoid ()
1/(1-e^z)
large numbers approaches one
small (or larger negatives approach 0)
Cost function
Lost function
(single training example)
want y^ = y (from training data)
L(y^, y)
Cost function
(measures full training set)
vocabulary
linear algebra
calculus
implementation
numpy
np.array()
np.array?
# Documentation
.shape()
"broadcasting"