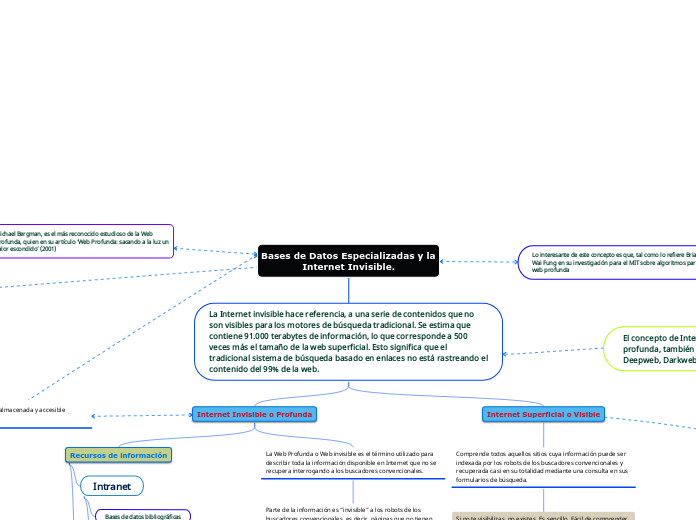
Bases de Datos Especializadas y la Internet Invisible.
La Internet invisible hace referencia, a una serie de contenidos que no son visibles para los motores de búsqueda tradicional. Se estima que contiene 91.000 terabytes de información, lo que corresponde a 500 veces más el tamaño de la web superficial. Esto significa que el tradicional sistema de búsqueda basado en enlaces no está rastreando el contenido del 99% de la web.
Internet Invisible o Profunda
Recursos de información
Intranet
Bases de datos bibliográficas
Catálogos de bibliotecas
Otras bases de datos bibliográficas
Bases de datos alfanuméricas
Obras de referencia: diccionarios, enciclopedias...
Estadísticas y bases de datos numéricos
Bases de datos textuales
Web invisible
Páginas huérfanas
Páginas no textuales
Adobe Acrobat, Postcript
Ficheros multimedia y ejecutables
Acceso mediante pasarelas
Registros previos y palabras clave
Depósitos de documentos
Revistas electrónicas
Páginas dinámicas
La Web Profunda o Web invisible es el término utilizado para describir toda la información disponible en Internet que no se recupera interrogando a los buscadores convencionales.
Parte de la información es “invisible” a los robots de los buscadores convencionales, es decir, páginas que no tienen una URL fija y que se construyen en el mismo instante (temporales) desapareciendo una vez cerrada la consulta.
Conocer el funcionamiento de los motores de búsqueda es fundamental para comprender el porqué de la Internet Invisible, ya que la supuesta invisibilidad de la información deriva de la tecnología y política de los buscadores para indexar los sitios porque cada buscador posee una gran base de datos y es allí donde busca ante una consulta y no en toda la web.
Internet Superficial o Visible
Comprende todos aquellos sitios cuya información puede ser indexada por los robots de los buscadores convencionales y recuperada casi en su totalidad mediante una consulta en sus formularios de búsqueda.
Si no te visibilizas, no existes. Es sencillo. Fácil de comprender. Puede que tu negocio tenga el mejor personal y ofrezca el sobresaliente servicio, pero si no estás visibilizado no tendrás clientes. No irán porque no sabes que existes.
Lo interesante de este concepto es que, tal como lo refiere Brian Wai Fung en su investigación para el MIT sobre algoritmos para web profunda
De acuerdo con una investigación conducida por la Universidad de Berkeley en California, en 2003 la web (superficial) contenía aproximadamente 167 terabytes de información
Michael Bergman, es el más reconocido estudioso de la Web Profunda, quien en su artículo ‘Web Profunda: sacando a la luz un valor escondido’ (2001)
Se acuñó el término haciendo referencia a la expresión ‘Internet invisible’ que había sido usada por Jill Ellsworth ya en 1994
Momento en el cual se pronosticaba el boom del .com y el crecimiento exponencial de la web y la consecuencia ampliación del acceso a la información y el conocimiento.
Generalmente es información almacenada y accesible mediante bases de datos.

¿Cómo se clasifica?
Web Opaca
Compuesta por archivos que no están incluidos en los índices de los buscadores por alguno de los siguientes motivos:
Extensión de la indización: a veces, por economía, no todas las páginas de un sitio son indizadas en los buscadores.
Frecuencia de la indización: los buscadores no poseen la capacidad de indizar todas las páginas existentes; a diario se agregan y modifican muchas y la indización no se realiza al ritmo que permita incluirlas a todas.
Número máximo de resultados visibles: aunque los motores de búsqueda arrojan a veces un gran número de resultados, generalmente limitan el número de documentos que se muestran (entre 200 y 1000).
URL desconectadas: las generaciones más recientes de buscadores, presentan los documentos por relevancia basada en el número de veces que aparecen referenciados en otros.
Web Privada
Consiste en las páginas Web que podrían estar indizadas en los buscadores pero son excluidas deliberadamente por alguno de estos motivos:
Las páginas están protegidas por contraseñas.
Contienen un archivo “robots.txt” para evitar ser indizadas.
Contienen un campo “noindex” para evitar que el buscador pueda indizar la parte correspondiente al cuerpo de la página. Este segmento de la Web contiene documentos excluidos deliberadamente por su falta de utilidad.
Web Propietaria
Incluye aquellas páginas en las que es necesario registrarse para tener acceso al contenido, ya sea de forma gratuita o arancelada.
En buena parte de la web propietaria los contenidos se cierran con una finalidad económica: hay que pagar una tarifa por tiempo (día, año) o por contenido (artículo, ejemplar de un diario) para acceder a la información.
Web Realmente Invisible
Se compone de páginas que no pueden ser indizadas por limitaciones técnicas de los buscadores, como las siguientes:
Páginas web que incluyen formatos como PDF, PostScript, Flash, Shockwave, programas ejecutables y archivos comprimidos.
Páginas generadas dinámicamente, es decir, que se generan a partir de datos que introduce el usuario.
Información almacenada en bases de datos relacionales, que no puede ser extraída a menos que se realice una petición específica.
Otra dificultad consiste en la variable estructura y diseño de las bases de datos, así como en los diferentes procedimientos de búsqueda.

El concepto de Internet invisible o Internet profunda, también es conocido como Deepweb, Darkweb o Hidden web
Buscadores
Tipos
Jerárquicos
Son organizados y clasifican los resultados de la búsqueda según la relevancia que tiene el sitio en el buscador web. Recopilan toda la información de los contenidos que tienen relación con la búsqueda que realiza el usuario.
Metabuscadores
Recopilan la información de varios motores de búsqueda para ofrecer un resultado general de la consulta realizada, es decir permiten buscar en varios buscadores al mismo tiempo.
Directorios
Listas de recursos organizados por categorías generales, se estructuran jerárquicamente ofreciendo enlaces directos a otros recursos de Internet.

Función
Sistemas informáticos que recopilan información en Internet con el objetivo principal de mostrar la información previamente solicitada a los usuarios.
Es decir, los buscadores dan a los usuarios la oportunidad de encontrar en Internet la información que necesitan de una forma rápida y sencilla mediante consultas de búsqueda.
Información académica y científica que ofrece la internet superficial y la invisible.
Invisible
Se denomina Internet Académica Invisible al conjunto de bases de datos y colecciones relevantes para la academia, o con fines académicos, que no es posible ser buscado por los motores de búsqueda convencionales
Dentro de estos documentos se pueden encontrar artículos, libros, reportes, documentos de acceso abierto, datos de encuestas, entre otros.
La preocupación sobre este tema radica en que millones de documentos permanecen invisibles frente a los ojos de los usuarios convencionales.
El problema con los motores de búsqueda convencionales es que no muestran aquellos datos que cambian constantemente, y dicha información, al cambiar de manera tan rápida es imposible de ser indexada por lo que restringe su aparición en los motores de búsqueda convencionales.
Superficial
Generalmente la búsqueda de información académica es mucho más fácil de acceder y no necesita registrarse para verla o descargarla, aunque los datos que nos dan alli no
tienen tanta profundización y a veces es irrelevante y que
toca ir a otra pagina a buscar.
Respecto a la información científica, resulta muy difícil encontrar datos específicos o realmente confiables que nos ayuden en los temas que necesitamos, esto por la web de fácil acceso que brinda la internet superficial y la poca información que tiene en cada buscador