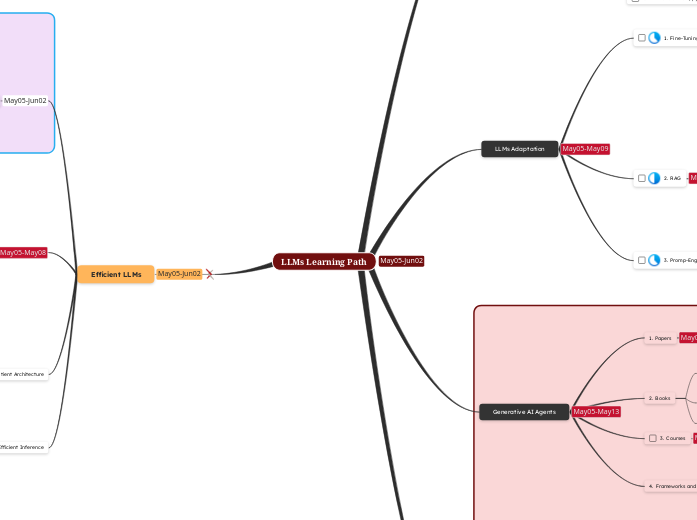
LLMs Learning Path
地図を中央に表示する
には、ここをクリックしてください。
地図を中央に表示する
には、ここをクリックしてください。
プレゼンテーションが終了しました
リスタート
ノート
{title}
{assignedTo}
開始
終了
投票する
リンク
リンクがクリップボードにコピーされました。
コメントを追加。
レベルを表示
1
2
3
全て