
"Estadística Aplicada A la Ingeniería"
-De Lira Raygoza Erika Yasmin (180275).
-López De Luna Dulce Rosario (190235).
-Montoya Honorato Jaffet (191481).
-Muro Delgado Luis (191536).
-Ornelas Cuevas Yesenia Jazmín (191049).
-Ortega Juárez Viridiana Guadalupe (191187).
-Rodríguez González Cristián Isaac (190934). ISP 7º "B"
Estadística Descriptiva
Análisis de datos.
Es la ciencia que examina datos en bruto con el propósito de sacar conclusiones sobre la información.
Base de datos.
Población.
Todos los
elementos o individuos
de análisis.
Muestra.
Subconjunto de
la población.
Variable.
Una
característica
que evalúas
del los
individuos.
Datos.
Los valores que
adquieren las variables.
Medidas de posición.
PERCENTILES.
Son los valores
que dividen en cien partes
iguales el conjunto de datos
ordenados. Ejemplo, el
percentil de orden 15 deja
por debajo al 15% de las
observaciones, y por encima
queda el 85%
CUARTILES.
Son los tres
valores que dividen al
conjunto de datos ordenados
en cuatro partes iguales.
DECILES.
Son los nueve
valores que dividen al
conjunto de datos ordenados
en diez partes iguales.
Medidas de centralización.
Media.
La media se representa con X
barra y su fórmula es la
siguiente.
Donde :
X = Media.
n = Cantidad de valores
observados.
xn = Valor observado.
Σ Sumatoria de todos los
datos individuales
Su cálculo es muy sencillo y en él intervienen todos
los datos.
Su valor es único para una serie de datos dada.
Se usa con frecuencia para comparar serie de
datos, aunque es más apropiado acompañarla de
una medida de dispersión.

Fórmula.
Ejemplo:
Un técnico midió la resistencia de cinco bobinas y
anotó los resultados en ohms los valores obtenidos
fueron. 3.35, 3.37, 3.28, 3.34, 3.30. x= 3.35+3.37+3.28+3.34+3.30/5= 3.33
Mediana.
La mediana es el valor que corresponde al punto
medio de los valores después de ordenarlos de
menor a mayor.
Cincuenta por ciento de las observaciones son
mayores que la mediana, y 50% son menores que
ella.
Para un conjunto par de valores, la mediana será el
promedio aritmético de los dos valores centrales.
Es única; esto es, a semejanza de la media, sólo existe una
mediana para un conjunto de datos.
No se ve afectada por valores extremadamente grandes o
muy pequeños, y por tanto es una medida valiosa de
tendencia central cuando se presentan valores dispersos.
No es recomendable para operaciones algebraicas.
Ejemplo:
Las edades de una muestra de 5 estudiantes del colegio son:
21, 25, 19, 20, 22
Ordenando los datos en forma ascendente, tenemos: 19, 20,
21, 22, 25. Entonces la mediana es 21.ya que este se encuentra en medio de los 5
datos.
Las estaturas de 4 jugadores de basquetbol, en pulgadas, son:
76, 73, 80, 75.
Entonces la mediana es 75.5, ya que los datos 73 y 80 están en medio se
suman se dividen entre dos.
La moda.
La moda es el valor de la observación que
aparece con más frecuencia.
Ejemplo:
Las calificaciones de 10 estudiantes son:
81, 93, 84, 75, 68, 87, 81, 75, 81, 87
Dado que 81 es el dato que aparece con más
frecuencia, éste es la moda.
Medidas de dispersión.
La segunda medida
de los datos es la de
dispersión esta nos
ayudan a determinar
que tan lejos del valor
central se encuentran
los datos en forma
individual.
Rango.
El rango en una serie de datos es la diferencia
entre el valor mayor y el valor menor. Su expresión
matemática es.
R = X max – X min
Donde .
R = Rango de la serie de datos.
X max = Valor mayor.
X min = Valor menor.
Ejemplo:
Un técnico midió la resistencia de cinco bobinas y
anotó los resultados en ohms los valores obtenidos
fueron. 3.35, 3.37, 3.28, 3.34, 3.30. ¿cuál es el
rango de estos datos?
X max = 3.37
X min = 3.28.
R = 3.37 – 3.28
R = 0.09
Varianza.
Es una medida estadística que
evalúa la dispersión de los
valores respecto a un valor
central (media), es decir, la
media de las diferencias
cuadráticas de las
puntuaciones respecto a su
media aritmética. Suele ser
representada con la letra S2.
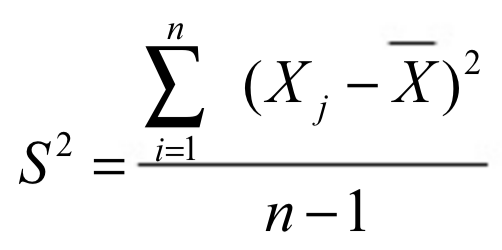
Fórmula.
Un técnico midió la
resistencia de cinco
bobinas y anotó los
resultados en ohms los
valores obtenidos
fueron. 3.35, 3.37, 3.28,
3.34, 3.30. ¿cuál es la
varianza de estos
datos?
Xi Xi-Promedio (Xi-Promedio)2
3.35 3.35-3.328= 0.022 (0.022)2=0.000484
3.37 3.37-3.328=0.042 (0.042 )2=0.001764
3.28 3.28-3.328=-0.048 (-0.048 )2=0.002304
3.34 3.34-3.328=0.012 (0.012 )2=0.000144
3.3 3.3-3.328=-0.028 (-0.028 )2=0.000784
Promedio=3.328 n=5 Suma =0.005
S2=0.00548/5 1=0.00137
Desviación estándar.
Debido a que los valores de
la varianza están al
cuadrado, es necesario un
valor representativo de las
unidades que se manejan en
los datos, de aquí la
necesidad del uso
generalizado de la
desviación estándar.
La desviación estándar es la
raíz cuadrada positiva de la
varianza. Se simboliza por S
Fórmula.
Ejemplo:
Un técnico midió la
resistencia de cinco
bobinas y anotó los
resultados en ohms los
valores obtenidos
fueron. 3.35, 3.37, 3.28,
3.34, 3.30. ¿cuál es l
desviación estándar de
estos datos?
Como el valor de S2
ya lo calculamos solo
sustituimos los datos en
la fórmula.
S= √0.0370
S= 0.00137
Rango Intercuartil.
El rango intercuartil representa la diferencia entre
el cuartil 1 y el cuartil 3 esto es Q1-Q3.
Es útil como medida de dispersión cuando se usa la
mediana como medida de centralización.
Se emplea en la construcción del diagrama de caja
y bigotes.
Ejemplo:
Para el ejemplo de las lecturas de resistencia
eléctrica.
Q1=3.30
Q3=3.35
Rango intercuartil =0.05
Coeficiente de variación o Pearson.
Es una medida de
dispersión útil para
comparar dispersiones a
escalas distintas pues es
una medida que no se
ve afectada ante
cambios de escala. Se
simboliza con las letras
Cv.
Fórmula.
Su fórmula es
desviación estándar
entre el promedio.
Cv=S/X
Ejemplo:
Un técnico midió la
resistencia de cinco
bobinas y anotó los
resultados en ohms los
valores obtenidos
fueron. 3.35, 3.37, 3.28,
3.34, 3.30. ¿cuál es es
coeficiente de variación
de estos datos?
Cv=0.0370/3.33=0.011
Medidas de forma.
Sesgo o asimetría.

El sesgo es positivo si
la cola de la
distribución se localiza
a la derecha y
viceversa.
Curtosis.

Nos indica el grado de
apuntamiento de una
distribución con
respecto a una
distribución normal.
Platicurtica curtosis<0
Mesocurtica curtosis=0
Leptocurtica curtosis>0
Software estadístico.
Existe una gran
cantidad de software
estadístico el cual no
ayuda a realizar un
procesamiento de datos
de una manera más
rápida y precisa.
Existen aplicaciones
gratuitas, comerciales,
de código abierto o
inclusive como
adicionales a otras
aplicaciones.
Gratuitas:
R project.
Scilab.
PSPP.
Comerciales:
Excel.
Minitab.
SPSS.
Statgraphics.
Medidas de datos y Excel.
El proceso de cálculo
de las medidas de
posición y dispersión
se vuelve laborioso
cuando se realiza a
mano o calculadora.
Excel es una
herramienta que nos
facilita el cálculo de
estas.
Medidas de posición.
A1:A2 es cualquier rango de celdas. 1,2,3 0 4 es el
cuarti
Cuartil
=CUARTIL.INC(A1:A2,0,1,2,3 o 4)
Ejemplo para el cuartil 1
=CUARTIL.INC(A1:A20,1)
Percentil
=PERCENTIL.INC(A1:A2,fracción percentil)
Ejemplo para el percentil 65.
=PERCENTIL.INC(A1:A20,0.65)
Medidas de centralización en Excel.
A1:A2 es cualquier rango de
celdas.
Media
=PROMEDIO(A1:A2)
Mediana
=MEDIANA(A1:A2)
Moda
=MODA(A1:A2)
Medidas de dispersión en Excel.
A1:A2 es cualquier rango de celdas.
Rango
=MAX(A1:A2)-MIN(A1:A2)
Varianza
=VAR(A1:A2)
Desviación
estándar =DESVEST(A1:A2)
Coeficiente de variación
=DESVEST(A1:A2)/PROMEDIO(A1:A2)
Rango Intercuartil
=CUARTIL.INC(A1:A2,4)-CUARTIL.INC
(A1:A2,1)
Medidas de forma en Excel.
A1:A2 es cualquier rango de celdas.
Curtosis
=CURTOSIS(A1:A2)
Asimetria
=COEFICIENTE.ASIMETRIA (A1:A2)
Análisis gráfico.
El análisis gráfico es
una forma sencilla de
presentar la
información y facilitar
su comprensión.
Histograma.
Un histograma es un
diagrama de barras, que
representa la distribución
de frecuencia de los datos
observados en un proceso
y los representa en forma
gráfica.
La gráfica de un
histograma consiste en un
plano cartesiano que
gráfica en el eje vertical
la frecuencia y en el eje
horizontal los datos
agrupados.
Un histograma nos permite observar de
manera objetiva el comportamiento de
una serie de datos. Un histograma nos
sirve para.
Identificar la posición y variabilidad de
un proceso.
Nos permite ver patrones de variación.
Elementos de un histograma.
Clase. Es cada una de
las barras, estas son un
subgrupo de los datos
representados.
Ancho de clase. Es el
rango de valores de
cada una de las clases.
Eje Vertical. Es el eje
en donde se cuantifica
la frecuencia.
Eje horizontal. Se
representa el intervalo
o ancho de cada una
de las clases.
Diagrama de caja y bigote.
Los diagramas de CajaBigotes (boxplots) son una
presentación visual que
describe varias características
importantes, al mismo tiempo,
tales como la dispersión y
simetría.
Para su realización se
representan los tres cuartiles
y los valores mínimo y
máximo de los datos, sobre
un rectángulo, alineado
horizontal o verticalmente.

Probabilidad
Fundamentos de la Probabilidad.
Probabilidad: La probabilidad es una
medida de la posibilidad
relativa de que un evento
ocurra en el futuro.
Experimento: es un proceso
que conduce a que ocurra
una (y solamente una) de
varias observaciones
posibles.
Resultado: es un suceso particular proveniente de
un experimento.
Ejemplo:
*Se lanza un dado no cargado una vez.
*El experimento es lanzar el dado.
*Los resultados posibles son los números 1, 2, 3, 4, 5 y 6.
*Un evento es la ocurrencia de un número par. Esto es, los números 2, 4 y 6.
Evento: es un conjunto de
uno o más resultados de un
experimento
Espacio Muestral: conjunto
de todos los posibles
resultados individuales
de un experimento aleatorio.
Ejemplo: Si el experimento se basa en el
lanzamiento de una moneda, el
espacio muestral tiene dos resultados, águila ( a ) y sello ( s ) *Y su espacio muestral sería.{ a , s }
Probabilidad Clasíca: Se basa en la consideración de que los resultados
en un experimento son igualmente posibles.
Ejemplo y formula:
Ejemplo:
¿Cuál es la probabilidad de que se
obtenga un número par al lanzar un dado?
Número de resultados favorables =3 (2,4,6)
Número de resultados posibles=6
Probabilidad= 3/6=0.5.
Formula:
Probabilidad = Resultados probables/ Resultados posibles
Probabilidad Subjetiva: Si no existen datos o experiencia en la que se pueda basar una probabilidad
Ejemplo: Estimar la posibilidad de que el equipo de las Chivas participe en la final del torneo.
Eventos mutuamente excluyentes: si la
ocurrencia de cualquiera significa que ninguno de
los otros eventos puede ocurrir al mismo tiempo.
Ejemplo: Si lanzo una moneda no puede caer águila y sol al
mismo tiempo.
Colectivamente exhaustivo: Por lo menos uno de los eventos debe de ocurrir
cuando se realiza un experimento.
Ejemplo: La probabilidad de que al lanzar una moneda salga águila es 0.5 y que salga sello es 0.5 la suma de ambos eventos es 1.
Reglas de Probabilidad de Varios Eventos
Regla especial de adición:
Si los eventos A1, A2,.. An son mutuamente excluyentes, la regla especial de la adición indica que la probabilidad de que ocurra uno u otro de los eventos, es igual a la suma de sus probabilidades.
Formula:
P(A1, A2,.. o An) = P(A1) +P(A2)+.. P(An)
Regla del complemento:
Requisitos los eventos deben de ser mutuamente excluyentes y colectivamente exhaustivos.
*La regla del complemento es utilizada para determinar la probabilidad de que un evento ocurra, restando a 1 la probabilidad de que no ocurra dicho evento.
Formula:
Si P(A) es la probabilidad de un
evento A y P(~A) es la probabilidad del complemento de A, P(A) + P(~A) = 1 o P(A) = 1 – P(~A)
Regla general de la adición:
Probabilidad conjunta:
Es la probabilidad que evalúa la posibilidad de que
dos o más eventos ocurran en forma simultanea.
Ejemplo:
En una muestra de
500 estudiantes, 225
afirmaron tener un estéreo, 175 dijeron tener una TV, y 100 afirmaron tener ambos.
Manera de ejercer:
* P(Stereo) = 225/500 = 0.45
* P(TV) = 175/500 = 0.35
* P(Stero y TV) = 100/500 = 0.20
Regla especial de la multiplicación:
Para la aplicación de esta regla se requiere que los eventos sean independientes.
Ejemplo:
Lanzar dos monedas, que salga águila o sol en una no tiene nada que ver con que salga águila o sol en la otra.
Formula:
P(A y B)= P(A) * P(B)
Regla general de la multiplicación:
La regla general de la multiplicación es utilizada para
encontrar la probabilidad conjunta de que dos o mas eventos ocurran y estos eventos son dependientes y condicionales.
Formula:
P(A y B)=P(A)*P(BlA)
Técnicas de Conteo
Principio Multiplicativo:
Este principio se usa cuando la
actividad lleva una serie de pasos.
Formula:
N1 x N2 x ..........x Nr
maneras o formas
Ejemplo:
Contamos con tres pares de
zapatos de diferente estilo así como con 4 pantalones y 5 camisas. ¿De cuantas formas diferentes nos podemos vestir?
* Número de zapatos = 3
* Número de pantalones = 4
* Número de camisas = 5
* Número de formas de vestir = 3x4x5=60.
Principio aditivo:
Si se desea llevar a efecto una
actividad, la cuál tiene formas alternativas para ser realizada
Formula:
M + N + .........+ W
maneras, formas o alternativas.
Diagrama de arbol:
Es una representación gráfica de los posibles resultados del experimento, el cual consta de una serie de pasos, donde cada uno de estos tiene un número finito de maneras de ser llevado a cabo. Se utiliza en los problemas de conteo y probabilidad.
Combinación y Permutación
Combinación:
Es todo arreglo de elementos en donde no nos interesa el lugar o posición que ocupa cada uno de los elementos que constituyen dicho arreglo.
Ejemplo:
El ejercicio te pedira de manera que sabras que no importa el orden del resultado.
Formula:
Permutación:
Es todo arreglo de elementos en donde el lugar o posición
que ocupa cada uno de los elementos que constituyen dicho arreglo es un resultado posible, es decir el orden importa.
Ejemplo:
El ejercicio te pedira de manera ordenada los datos y ahi sabras que es permutacion.
Formula:
Estadística inferencial.
Distribuciones de probabilidad.
Variable aleatoria.
Una variable aleatoria es un valor numérico determinado por el resultado de un experimento.
Discreta.
Una variable discreta puede asumir sólo valores claramente separados. Estos valores surgen de un proceso de conteo.
Ejemplos.
•El número de autos entrando en un auto lavado por hora. •El número de clientes que llegan a un banco cada hora. •El numero de partes defectuosas en una fábrica. •El número de defectos en una envase. •El numero de poros de una pieza pintada.
Continúa
Una variable continua puede asumir un número
infinito de valores dentro de un rango determinado.
Estos valores surgen de un proceso de medición.
Ejemplos.
•La densidad de la leche.
•La resistencia eléctrica
de un arnés.
•El tiempo invertido en
una llamada telefónica.
• La resistencia de una
pieza metálica.
Distribuciones de probabilidad.
Una distribución de probabilidad es la lista de todos los resultados posibles de un experimento (variable) y la correspondiente probabilidad.
Discreta.
Binomial.
Poisson.
Hypergeometrica
Bernoulli
Continúa.
Normal
T student
Ji cuadrada
Características
•Las distribuciones de probabilidad se grafican en un plano cartesiano x-y. En el eje y se representa la probabilidad y en el eje los posibles resultados. •La suma de las probabilidades es 1.00. •La probabilidad de un resultado particular es un número mayor o igual a cero y menor o igual a uno. •Los resultados son mutuamente excluyentes.
Distribuciones de probabilidad discretas.
Binomial.
Describe el número de éxitos al realizar n experimentos independientes entre sí, acerca de una variable aleatoria.
Características
•El resultado de cada ensayo de un experimento se clasifica en una de dos categorías mutuamente excluyentes éxito o fracaso. Pasa o no pasa. •La variable aleatoria cuenta el número de éxitos en una cantidad fija de ensayos. •La probabilidad de un éxito permanece igual en todos los ensayos. Lo mismo sucede con la probabilidad de un fracaso. •Los ensayos son independientes.
Ejemplos
•La inspección de piezas bajo un criterio de pasa o no pasa el producto. •La calificación de un examen en donde las preguntas son correctas o incorrectas esto es el caso de respuestas falso/verdadero o de una opción de varias. •Un estudio sobre trabajadores empleados o desempleados.
Formula.
•C es una combinación.
•n es el número de ensayos.
•p es la probabilidad de éxito en cada ensayo.
•x es el número de éxitos.
Poisson.
Permite determinar la probabilidad de un resultado específico de una serie de resultados que se distribuyen en intervalos o segmentos como distancia, tiempo, espacio, área u otro.
Características.
•La variable debe ser discreta y se define como el número de resultados por segmento o unidad.
•Los resultados entre los diferentes segmentos deben ser independientes.
•Los resultados obtenidos en cada segmento obedecen a un comportamiento aleatorio.
Ejemplos.
•El número de clientes que llega a una taquilla por hora. Número de clientes es variable y hora es el segmento.
•El número de llamadas telefónicas recibidas en un call center durante el día.
•El número de chispas de chocolate en una galleta.
•El número de errores en una factura.
•El número de defectos de una puerta en un proceso de pintura automotriz.
Formula.
•X es el número de éxitos en por segmento promedio del experimento probabilístico. •P(x) es la probabilidad de ocurrencia del número de éxitos x en un segmento determinado. •∆ es la ocurrencia de éxitos en el segmento que se desea determinar la probabilidad y es igual a x(éxitos promedio) *n (Valor del segmento). •e es la base de los logaritmos naturales 2.718.
¿Qué es la distribución normal?
La distribución normal es una distribución con forma de campana donde las desviaciones estándar sucesivas con respecto a la media establecen valores de referencia para estimar el porcentaje de observaciones de los datos. Estos valores de referencia son la base de muchas pruebas de hipótesis, como las pruebas Z y t.
Características distribución normal.
• La distribución de probabilidad normal es una distribución continua.
• La distribución de probabilidad normal es simétrica con respecto a su media.
• La curva normal es acampanada y presenta sólo un pico en el centro de la distribución.
• La curva normal depende de los parámetros y en consecuencia existen un número infinito de distribuciones normales.
Aplicaciones de la distribución normal.
• Caracteres morfológicos de individuos como la estatura.
• Caracteres fisiológicos como el efecto de un fármaco
• Caracteres sociológicos como el consumo de cierto producto por un mismo grupo de individuos.
• Caracteres psicológicos como el cociente intelectual.
• Nivel de ruido en telecomunicaciones.
• Proceso de medir ciertas magnitudes como masa, volumen, flujo etc.
Distribución normal estándar.
Existe un gran número de distribuciones normales cuyos valores estadísticos de posición µ y dispersión σ son muy variados al punto que podríamos decir que cada distribución normal es única.
Esto en conjunto con la complejidad de la función de probabilidad normal f(x) nos lleva a que el cálculo de la función de probabilidad se vuelva compleja.
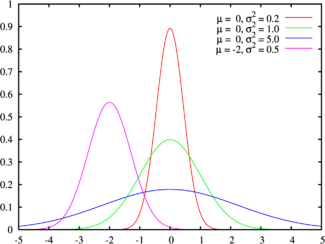
Características Curva Normal Estándar.
• La distribución normal estándar es una distribución normal con media cero y desviación estándar de 1
• También es llamada distribución
z.
• Un valor z es la distancia entre un valor seleccionado llamado x, y la media de la población µ, dividida entre la desviación estándar, σ.
• Los valores de Z van sobre el eje horizontal de la CNE (Curva Normal Estándar) por lo regular se dan valores desde -3 hasta 3 pasando por 0.
Valor Z.
La fórmula para obtener el valor estandarizado, esto es, convertir el valor de variable en estudio x en el valor z esta dado por la imagen que se muestra a la derecha.
• Donde.
• X valor de la variable.
• Es la media poblacional.
• La desviación estándar poblacional.
Probabilidad valor Z.
Formulas:
DISTR.NORM.ESTAND
• Esta función permite evaluar la probabilidad o área bajo la curva del valor z.
• Funciona de la siguiente forma. =DISTR.NORM.ESTAND(Z)
• Mismo ejemplo de la tabla antes usada.
= DISTR.NORM.ESTAND(0.43)
Respuesta 0.6664
DISTR.NORM.ESTAND.INV
• Realiza el proceso inverso que
DISTR.NORM.ESTAND es decir dado un valor de probabilidad o área de la curva te regresa el valor de Z.
• Usando el ejemplo anterior.
=DISTR.NORM.ESTAND.INV (0.6664)
Resultado 0.43
Regresión Lineal.
Intervalo de Confianza.
Características:
-El tamaño de la selección de la muestra depende de la proporción de datos que se utilicen para el calculo del valor muestral.
-Este informa en que porcentaje de casos la estima es certera.
-Frecuentemente los niveles oscilan entre el 95% y el 99%.
-El margen de error de la estimación se señala como alfa y marca la probabilidad que existe para que el valor de población esté fuera del intervalo.
El intervalo de confianza describe la variabilidad entre la medida obtenida en un estudio y la medida real de la población
Técnicas de Muestreo.
Probabilísticas.
Aleatoria Simple.
Población Finita.
Una muestra aleatoria simple de tamaño n, de una población finita de tamaño N, es una muestra seleccionada de tal manera que cada muestra posible de tamaño n tenga la misma probabilidad de ser seleccionada.
Procedimiento
Para identificar una muestra aleatoria simple a partir de una población finita es seleccionar uno por uno los elementos que constituyen a la muestra, de tal modo que cada uno de los elementos que aún queden en la población tenga la misma probabilidad de ser seleccionados.
Población Infinita.
Una muestra aleatoria simple de una población infinita es aquella que se selecciona en tal forma que se satisfacen las siguientes condiciones.
1. Cada elemento seleccionado proviene de la misma población.
2. Cada elemento se selecciona en forma independiente.
Un ejemplo de esta situación seria el tiempo que transcurre entre colocar una solicitud de compra y la llegada del producto solicitado. Podemos concluir que el número de tiempos posibles es infinito y no podemos listar todas las posibilidades.
Estratificada.
En este tipo de muestreo, primero se divide a la población en grupos de elementos llamados estratos, de tal manera que cada elemento en la población pertenece a uno y sólo a un estrato.
Características:
• Los estratos deben formarse de tal manera que se garantice la independencia entre los estratos. Es decir, los estratos deben ser completamente independientes en el proceso de selección y de estimación.
• Las mediciones dentro de los estratos deben ser homogéneas (baja variabilidad).
• Las mediciones entre estratos deben ser heterogéneas (alta variabilidad).
Después de formar los estratos se toma una muestra aleatoria simple de cada uno de ellos.
Conglomerados.
Se divide a la población en conjuntos, cada elemento de la población pertenece a uno y a un solo grupo, este muestreo tiende a proporcionar los mejores resultados cuando son desiguales.
Sistemático.
Implica a seleccionar al azar uno de los elementos de la lista de población y el resto de las muestras se tomarían cada cierto numero de elementos. Debido a que se selecciona al azar se considera un factor aleatorio en selección del resto de la muestra.
Un ejemplo de esta situación seria, si se desea una muestra de tamaño 50 de una población con 5000 elementos, podemos muestrear un elemento de cada 100 en la población e implica seleccionar ala azar uno de los primeros 100 elementos de la lista de la población y el resto de las muestras se tomarían cada 100 muestras.
No Probabilísticas.
Por Conveniencia.
Se realiza bajo la base de la facilidad que este dé al investigador.
Un ejemplo de esto son las investigaciones que se realizan solicitados voluntarios o aquellos que se realizan en animales salvajes.
Por Juicio.
En este método, la persona más capaz o con mayor experiencia en el proceso a estudiar selecciona a los elementos de la población que siente son los más representativos.
Un ejemplo seria realizar un censo de opinión en el senado por un reportero, el reportero puede muestrear a dos o tres senadores, considerando que ellos reflejan opinión general de todos los senadores.