Clustering
Proceso de aprendizaje de un modelo que dilucida diferentes clases predeterminadas de datos.
Particionamiento jerárquico basado en distancia
Aprendizaje Probabilístico
Agrupación jerárquica Aglomerativa
Agrupación de particiones

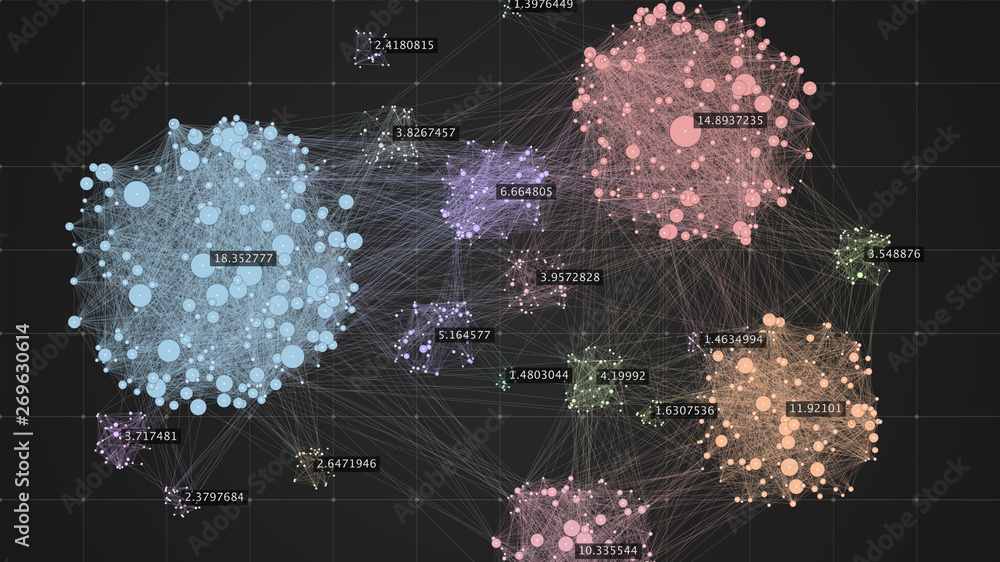
Esta función mapea los datos en uno de los múltiples clústeres donde la disposición de los elementos de datos se basa en las similitudes entre ellos.
Simplificaciones Detección de patrones
Útil en la construcción de conceptos de datos Proceso de aprendizaje no supervisado
Recuperación de información

Se proporcionaron datos sin etiquetar
Métodos utilizados para analizar los conjuntos de datos y dividirlos sobre la base de algunas reglas de clasificación particulares o la asociación entre objetos
Categoriza los datos con la ayuda de los datos de entrenamiento proporcionados

Aprendizaje sin supervisión
Función de similitud
Extraer referencias de conjuntos de datos que consisten en datos de entrada sin respuestas etiquetadas
Se utiliza como un proceso para encontrar una estructura significativa, procesos subyacentes explicativos, características generativas y agrupaciones inherentes a un conjunto de datos.