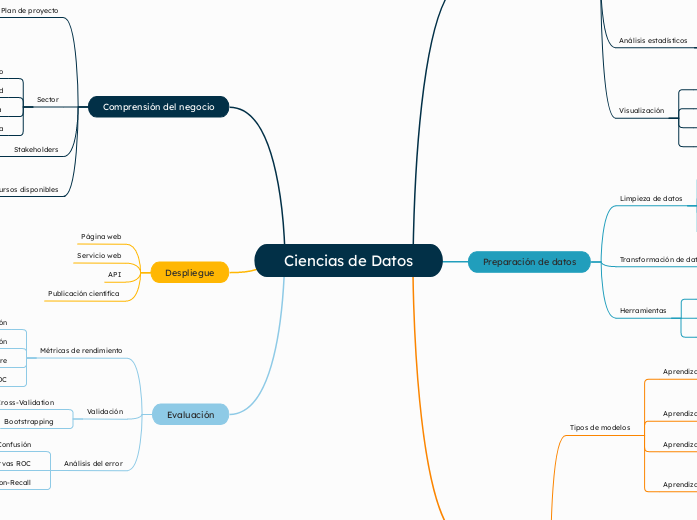
Ciencias de Datos
Compresión de datos
Fuentes de datos
Sector Gubernamental
Sector Privado
Datos abiertos
APIs
Web scraping
Tipo de datos
Estructurados
Base de datos
Semiestructurados
Json
XML
No estructurados
Texto
Imágenes
Archivos
Análisis estadísticos
Estadística descriptiva
Análisis de correlación
Valores atípicos
Visualización
Diagramas de dispersión
Histogramas
Gráficos de barras
Boxplots
Preparación de datos
Limpieza de datos
Eliminación de registros duplicados
Manejo de valores nulos
Imputación de datos
Corrección de errores
Transformación de datos
Normalización
Estandarización
Herramientas
R
Python
SQL
Modelado
Tipos de modelos
Aprendizaje supervisado
Regresión lineal y logística
Árboles de decisión
Aprendizaje no supervisado
K-Means
DBSCAN
Aprendizaje por refuerzo
Aprendizaje profundo
Redes Neuronales Convolucionales
Redes Neuronales Recurrentes
Transformadores
Entrenamiento del modelo
Datos
Entrenamiento
Validación
Prueba
Validación cruzada
Ajuste de hiperparámetros
Retos
Sobreajuste (Overfitting)
Subajuste (Underfitting)
Comprensión del negocio
Plan de proyecto
Objetivos
Alcance
Metas
Hipótesis
Resultados esperados
Sector
Gobierno
Salud
Economía
Ingeniería
Stakeholders
Grupos de interés
Recursos disponibles
Humanos
Técnicos
Tecnológicos
Despliegue
Página web
Servicio web
API
Publicación científica
Evaluación
Métricas de rendimiento
Precisión
MSE, MAE para regresión
F1-Score
AUC-ROC
Validación
K-Fold Cross-Validation
Bootstrapping
Análisis del error
Matriz de Confusión
Curvas ROC
Precision-Recall