af christophe Mias 4 år siden
267
HortonWorks
Hortonworks, l'éditeur de la plate-forme de données Hortonworks Data Platform (HDP), propose une solution basée sur Hadoop, intégrant des systèmes comme Hadoop Distributed File System (

af christophe Mias 4 år siden
267
L’accès en mode commande se fait via putty en mode ssh, à l’adresse 192.168.239.128.
Les codes utilisateurs sont root / hadoop et hue / 1111.
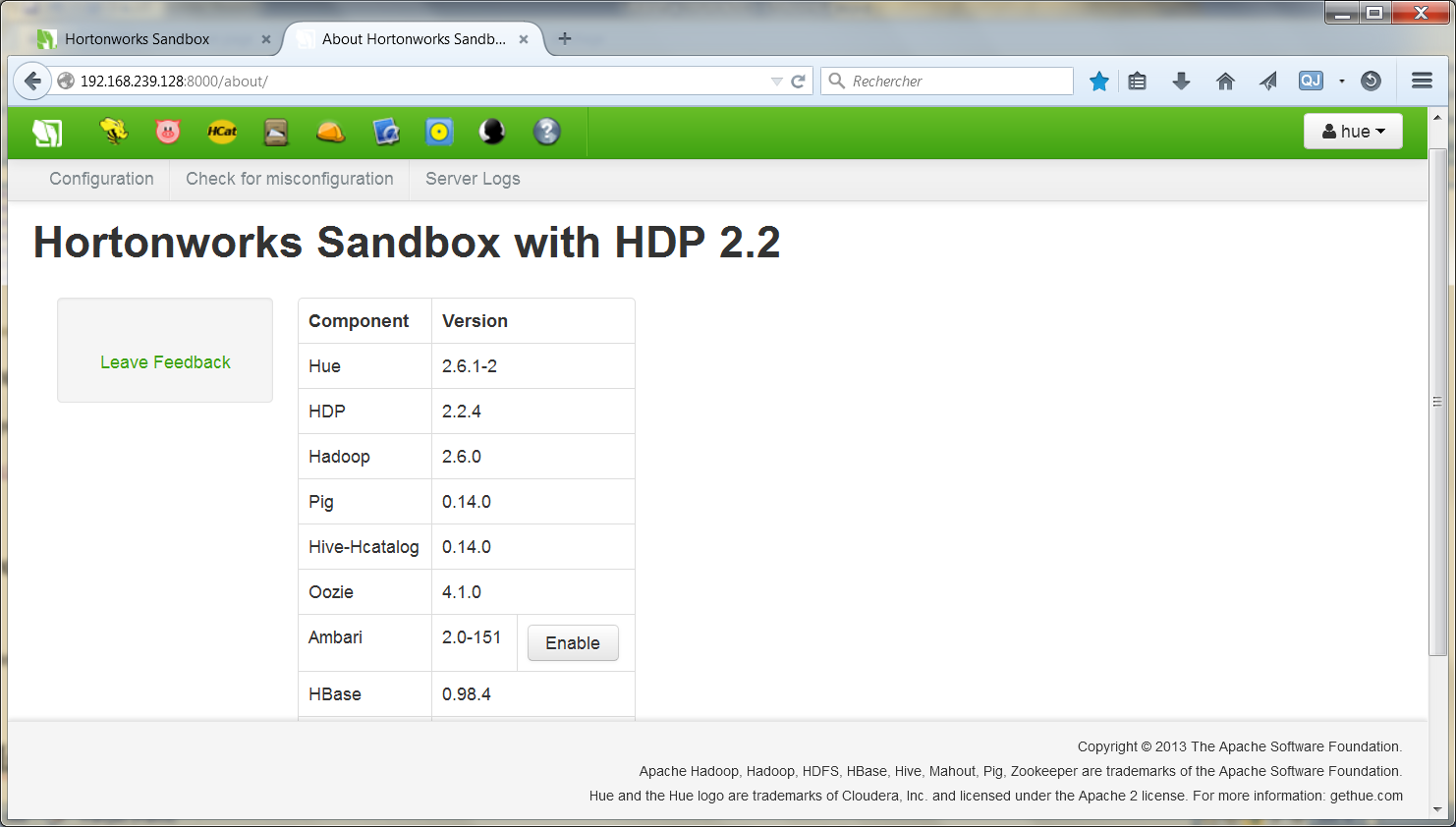
Dans votre navigateur Internet, entrez l’adresse
http://192.168.239.128:8000/about/
.
Vous avez ainsi accès aux différents outils qui seront utilisés dans ce tutoriel.
root
Ambari
.
Hortonworks est l'éditeur d'Hortonworks Data Platform (HDP), une plate-forme de données basée sur Hadoop qui comprend entre autres les systèmes Hadoop Distributed File System (HDFS), Hadoop MapReduce,
Nous allons successivement utiliser dans ce tutoriel les composants HDFS, MapReduce, Hive, Pig et HCatalog.
gestion des ressources:
nodes
containers
memoire
file d'attente/queues
etc.
Le cluster computing est confronté à plusieurs défis, tels que:
La plus grande limitation de la programmation MapReduce est que les tâches de mappage et de réduction ne sont pas sans état (state full). Cela signifie que les tâches de réduction doivent d'abord attendre la fin des tâches de carte. Cela limite le parallélisme maximal
ResourceManager
Le ResourceManager et l'esclave par nœud, le NodeManager (NM), forment le nouveau système générique de gestion des applications de manière distribuée.
Le ResourceManager est l'autorité ultime qui arbitre les ressources parmi toutes les applications du système. L'ApplicationMaster par application est, en fait, une entité spécifique au framework et est chargé de négocier les ressources du ResourceManager et de travailler avec le (s) NodeManager (s) pour exécuter et surveiller les tâches du composant.
a un connectables Scheduler , qui est responsable de l' allocation des ressources aux différentes applications en cours soumis à des contraintes connues des capacités, des files d' attente , etc. Le planificateur est un planificateur pur dans le sens qu'il effectue sans surveillance ou de suivi de l' état de l'application, l' offre aucune garantie sur le redémarrage des tâches ayant échoué en raison d'une défaillance de l'application ou de défaillances matérielles. Le planificateur exécute sa fonction de planification en fonction des besoins en ressources des applications; il le fait sur la base de la notion abstraite d'un conteneur de ressources qui incorpore des éléments de ressources tels que la mémoire, le processeur, le disque, le réseau, etc.
NodeManager
est l'esclave par machine, qui est chargé de lancer les conteneurs des applications, de surveiller leur utilisation des ressources (CPU, mémoire, disque, réseau) et d'en rendre compte au ResourceManager.
ApplicationMaster
L'application ApplicationMaster par application a la responsabilité de négocier les conteneurs de ressources appropriés à partir du planificateur, de suivre leur état et de surveiller la progression. Du point de vue du système, l'ApplicationMaster lui-même fonctionne comme un conteneur normal .
MapReduce
MapReduce est l'algorithme clé utilisé par le moteur de traitement de données Hadoop pour répartir le travail autour d'un cluster. Un travail MapReduce divise un ensemble de données volumineux en blocs indépendants et les organise en paires clé / valeur pour le traitement parallèle. Ce traitement parallèle améliore la vitesse et la fiabilité du cluster, renvoyant des solutions plus rapidement et avec une plus grande fiabilité.
La fonction Map divise l'entrée en plages par InputFormat et crée une tâche de carte pour chaque plage de l'entrée. Le JobTracker distribue ces tâches aux nœuds de calcul. La sortie de chaque tâche de mappage est partitionnée en un groupe de paires clé-valeur pour chaque réduction.
map(key1,value) -> list<key2,value2>La fonction Réduire recueille ensuite les différents résultats et les combine pour répondre au problème plus vaste que le nœud maître doit résoudre. Chaque réduction extrait la partition appropriée des machines sur lesquelles les cartes ont été exécutées, puis réécrit sa sortie dans HDFS. Ainsi, le réducteur est capable de collecter les données de toutes les cartes pour les clés et de les combiner pour résoudre le problème.
reduce(key2, list<value2>) -> list<value3>Le système actuel Apache Hadoop MapReduce est composé du JobTracker, qui est le maître, et des esclaves par nœud appelés TaskTrackers. Le JobTracker est responsable de la gestion des ressources (gestion des nœuds de travail, c'est-à-dire des TaskTrackers), du suivi de la consommation / disponibilité des ressources et de la gestion du cycle de vie des travaux (planification des tâches individuelles du travail, suivi de la progression, fourniture de la tolérance aux pannes pour les tâches, etc.)
Le TaskTracker a des responsabilités simples - lancer / démonter des tâches sur les commandes du JobTracker et fournir périodiquement des informations sur l'état des tâches au JobTracker.
Une seule machine physique est saturée de sa capacité de stockage à mesure que les données augmentent. Cette croissance s'accompagne du besoin imminent de partitionner vos données sur des machines distinctes. Ce type de système de fichiers qui gère le stockage des données sur un réseau de machines est appelé un système de fichiers distribué.
est un composant central d'Apache Hadoop et est conçu pour stocker des fichiers volumineux avec des modèles d'accès aux données en continu, s'exécutant sur des clusters de matériel de base. Avec Hortonworks Data Platform (HDP), HDFS est désormais étendu pour prendre en charge
supports de
au sein du cluster HDFS.
DataNode
noeuds où sont répartis les données
Blocks
NameNode
Metadonnée:
Le NameNode n'envoie pas directement de demandes aux DataNodes. Il envoie des instructions aux DataNodes en répondant aux pulsations envoyées par ces DataNodes. Les instructions incluent des commandes pour:
Mappage & arborescence
Le Namenode surveille activement le nombre de répliques d'un bloc. Lorsqu'une réplique d'un bloc est perdue en raison d'une panne de DataNode ou de disque, le NameNode crée une autre réplique du bloc. Le NameNode gère l'arborescence des espaces de noms et le mappage des blocs aux DataNodes, en conservant l'image entière de l'espace de noms dans la RAM.
Avec l'
architecture de données HDFS de nouvelle génération
fournie avec HDP, HDFS a évolué pour fournir
avec une veille à chaud, avec une résilience complète de la pile. La vidéo fournit plus de clarté sur HDFS.
replication
surveille la bonne réplications des blocs
langage de programmation de Hadoop
Apache Pig allows Apache Hadoop users to write complex MapReduce transformations using a simple scripting language called Pig Latin. Pig translates the Pig Latin script into MapReduce so that it can be executed within YARN for access to a single dataset stored in the Hadoop Distributed File System (HDFS).
Iterative data processing
Research on raw data
Extract-transform-load (ETL) data pipelines
Hive est un langage de requête similaire à SQL qui permet aux analystes familiarisés avec SQL d'exécuter des requêtes sur de gros volumes de données. Hive a trois fonctions principales: la synthèse des données, la requête et l'analyse. Hive fournit des outils qui facilitent l'extraction, la transformation et le chargement des données (ETL).
Les analystes de données utilisent Hive pour explorer, structurer et analyser ces données, puis les transformer en informations commerciales. Hive implémente un dialecte SQL (HiveQL) qui se concentre sur l'analyse et présente un riche ensemble de sémantiques SQL comprenant des fonctions OLAP, des sous-requêtes, des expressions de table communes et plus encore. Hive permet aux développeurs SQL ou aux utilisateurs disposant d'outils SQL d'interroger, d'analyser et de traiter facilement les données stockées dans Hadoop. Hive permet également aux programmeurs familiarisés avec le framework MapReduce de brancher leurs mappeurs et réducteurs personnalisés pour effectuer des analyses plus sophistiquées qui peuvent ne pas être prises en charge par les capacités intégrées du langage.
Les utilisateurs de Hive ont le choix entre 3 environnements d'exécution lors de l'
. Les utilisateurs peuvent choisir entre les frameworks Apache Hadoop MapReduce, Apache Tez ou Apache Spark comme backend d'exécution.
tez
ttmt par lot
WebHCat
Remarque: À un moment donné, HCatalog était son propre projet Apache. Cependant, en mars 2013,
le projet de HCatalog a fusionné
avec Hive. HCatalog est actuellement publié dans le cadre de Hive.



