Анализ
Одномерный статистический анализ (при анализе 2х и более групп с целью сравнения лишь одной переменной)
Гипотеза

Нулевая гипотеза - Ho - предполагает отсутствие различий между сравниваемыми выборками
Конкурирующая гипотеза - Н1 - о наличии различий между группами
Описательная статистика
Показатели
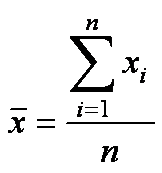
Среднее (mean) - вычисляется путем деления суммы значений переменной на количество значений
Медиана (median) – значение, которое занимает среднее положение среди точек данных, разбивая выборку на две равные части
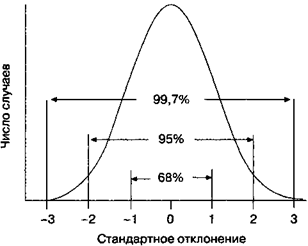
Стандартное отклонение отражает изменчивость (разброс, вариацию) значений переменной и оценивает степень их отличия от среднего

Стандартная ошибка (среднего) возможные отличия между значением среднего в анализируемой выборке, и истинным средним для всей популяции
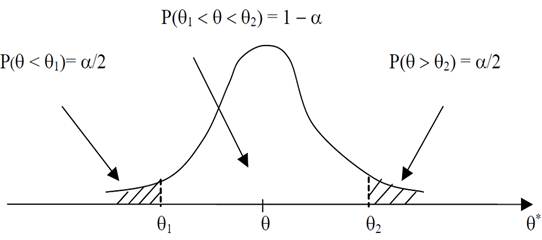
Доверительный интервал – диапазон значений, область, в которой с определенным уровнем надежности (или доверия) содержится истинное значение параметра
Статистическая мощность - вычисляется как 1 - β и означает вероятность сделать заключение о наличии различия, в то время как оно имеется на самом деле

Статистическая достоверность - показатель достоверности различий обозначается р - для конкретной выборки.
Если р≤0,05, то выявленное различие неслучайно и оно является достоверным.
Выбор одномерного статистического критерия
Зависит от:
типа данных (непрерывные или дискретные)
данные зависимые или независимые
распределение параметрическое (нормальное) или непараметрическое (отличное от нормального)
количества сравниваемых групп
Непараметрическая статистика - применяется к непрерывным и к дискретным данным
Непрерывные переменные
U тест Манна-Уитни
Тест Крускала-Уоллиса
Тест знаковых рангов Вилкоксона
Номинативные переменные
Точный тест Фишера
Хи-квадрат Пирсона
Тест МакНемара
Корреляционный анализ - проверяет взаимосвязь между какими-либо непрерывными данными; определяет характер взаимосвязи переменных (прямой или обратный)

+ Корреляция - если большие значения одной переменной имеют тенденцию к ассоциации с бόльшими значениями другой переменной
- Корреляция - если бόльшие значения одной переменной ассоциированы с меньшими значениями другой переменной (график по середине)
Корреляция отсутствует - нет никакой закономерности взаимосвязи одних показателей с другими (график справа)
Коэффициент корреляции - показатель согласованности между значениями двух переменных. Обозначается r (Pearson r), и имеет область значений от - 1 до + 1
Линейный регрессионный анализ - проверяет взаимосвязь между какими-либо непрерывными данными; определяет форму зависимости
y = a + bx;
где y - значение одной переменной, a – точка пересечения прямой с осью ординат (вертикальная ось, ось Y), b задает наклон линии, а х – значение другой переменной
Проводится, если корреляционный анализ выявил взаимосвязь между переменными
Чувствительность, специфичность и точность - отражают шансы поставить правильный диагноз заболевания у больных и здоровых людей
Чувствительность определяется как доля пациентов действительно имеющих заболевание среди тех, у кого тест был положительным
Чувствительность = а / (а+в)
Специфичность определяется как доля людей, не имеющих заболевания среди всех, у кого тест оказался отрицательным
Специфичность = г / (г+б)
Точность показывает долю «правильных срабатываний теста» среди всех обследованных и является совокупным показателем информативности теста
Точность = (а+г) / (а+б+в+г)
Анализ выживаемости и многомерная статистика
Анализ выживаемости
Методы анализа выживаемости - изучение закономерности появления ожидаемого события у представителей наблюдаемой выборки во времени.
Цензурированные данные - содержат неполную информацию. Наблюдаемый параметр является временем до наступления события, а период наблюдения ограничен
Исследование ЦД: построение таблиц дожития
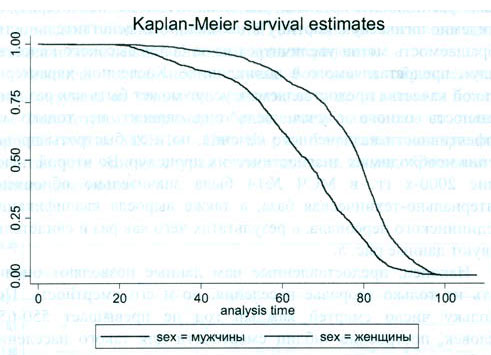
Исследование ЦД: метод Каплана-Мейера
Таблицы дожития
Метод Каплана-Мейера
Графическое представление метода
Построении кривой выживаемости, отражающей пропорцию пациентов, у которых ожидаемое событие не произошло к определенному моменту времени.
Для расчетов используется истинное количество объектов, у которых событие ещё не произошло в любой момент времени, для которого производится оценка
Лог-ранк тест
Модель Кокса - используется для анализа данных выживаемости
Многомерный анализ (используется для анализа двух и более групп, но с учетом одновременного изменения двух или более переменных)
Виды многомерного анализа

Множественная линейная регрессия используется для изучения изменения зависимой переменой (y) в ответ на различные значения других переменных (x1, x2, x3), которые представляют собой непрерывные переменные

Логистическая регрессия используется когда значение переменной результата является бинарным, например, выживаемость (да/нет), развитие заболевания (да/нет).
Модель пропорциональных интенсивностей Кокса оценивает шансы более раннего наступления события у членов изучаемой группы по сравнению с контрольной группой с помощью показателя отношения рисков (HR)
Взаимодействие между переменными - когда влияние фактора риска на исход (эффект) зависит от значения третьей синтетической переменной, составленной из двух исходных независимых переменных. При этом сама третья переменная не является независимым фактором риска или мешающей переменной.
Анализ качества модели - для оценки эффективности множественной линейной регрессии используется уже известный из корреляционного анализа коэффициент детерминации r2, который отражает степень рассеяния результата, возникающего благодаря вкладу многих переменных. Значение r2 варьирует в пределах от 0 до 1 и чем ближе оно к 1, тем лучше модель описывает результат.