Взять изначальное множество из интернета(либо из исходников, либо с гитхаба)
Сгенерировать самим
Как генерировать?
Равновероятно по грамматике
По грамматике с вероятностями
Откуда брать вероятности?
Если есть какое-то множество примеров, можно по частоте встречаемости нетерминалов в них.
По количеству поддеревьев в нетерминале.
Можно брать обратные вероятности Это позволит "мыслить" фаззеру в противоположном направлении. Плюсы: чаще будем покрывать неожиданные пути в грамматике. Минусы: чаще будем попадать в неинтересные символы(например в js часто будет вызываться return)
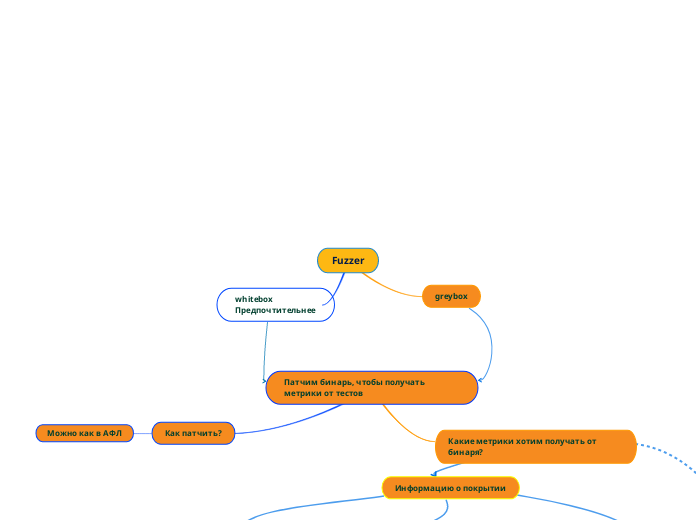
Как прогонять множество во время фаззинга?
Менять СРАЗУ всё поколение: Запускать все тесты и считать для каждого функцию качества
Минимизация размера
Запускать только один пример из очереди
Уменьшение поддерева
Рекурсивное замещение поддерева
Можно просто выкидывать поддеревья
Контролировать размер во время построение теста, если такое используется
Мутации
Скрещивание с другими тестами, путём замены поддеревьев
Замена поддерева на случайно сгенерированное
Для каждой вершинки в дереве считаем какую-то дополнительную информация и меняем, только на дерево с такой же инфомарцией. Например, тип нетерминала, количество переменных.
Если используется вероятностная грамматика, то в ней можно изменять случайно вероятности
Убрать из тестов семантические ошибки. Например, использование необъявленных переменных
Как понять, что тест успешный?
Функция(какая-то) от метрик, полученных при запуске, построении(сложность теста, покрытие, наличие эксепшона, длина)
Сложные рекурсивные тесты
Короткие
Покрытие веток(путей)
Подсчёт количества строк/функций, которые покрыл тест. Плюсы: просто (относительно) Минусы: метрика сама по себе не очень информативна. В контесте множества тестов можно выялять те, которые попадают в новые строки/функции.
Более детальный способ описывать покрытие. Метрика интересена только в контексте наличия других тестов. Плюсы: получаем более информативную оценку. Минусы: сложно реализовывать.
Информацию о покрытии
Какие свойства хотим получить у сгенерированных?
Из истории - чем код сложнее и рекурсивнее, тем вероятнее в нём есть баг.
Чем длиннее тест - тем он дольше будет выполняться, и тем сложнее будет разбираться в случае обнаружении бага
При генерации с равной вероятностью выбираем символ грамматики из текущей вершинки Плюсы: просто Минусы: работает хуже остальных. Например: будет часто вставлять терминальный символ вместо рамширения дерева.
Чем чаще встречается переход в тестах, тем чаще мы его будем использовать. Плюсы: просто пишется. Позволяет направлять фаззер, путём изменения множества. Выбор символа становится более осмысленным с точки зрения программирования. Минусы: нужно начальное множество
Если в вершине потенциально много поддеревьев, будем ходить туда чаще. Плюсы: позволит наиболее полно покрыть грамматику. Минусы: требуется предпосчёт количества деревьев для каждого нетерминала.
Как выбрать наиболее успешные?
Оставить какой-то процент тех, у кого максимальна функция качества
Выбрать несколько случайным образом
Провести "турнир" в случайном подмножестве и взять нескольких победителей.
Как понять нужен ли этот тест?
Исходя из контекста выбранной метрики. Например, если метрика - покрытие функций - и тест запустил новую функцию - то его оставляем.
Обработка успешных
Если в дереве грамматики есть вершина S с подвершиной S, то заменяем S на дочернюю вершину S
Перебираем все короткие поддеревья нетерминала и пытаемся заменить текущее
В superion используется стандартное покрытие AFL, а именно: считаются все ветки, которые покрыл тест, и количество проходов по ним
Функция самая простая: если покрытие увеличилось, считаем тест успешным
Берём все успешные тесты
Сначала парсим тест в AST(abstract syntax tree). Если происходит ошибка при парсинге, то делаем уменьшение по стратегии АФЛ: режем тест на чанки и последовательно пытаемся запустить без них, если покрытие не уменьшилось сохраняем изменения. Если ошибок не было, то поочерёдно выкидываем поддеревья и смотрим на покрытие, если не уменьшилось, выкидываем поддерево, заново парсим и начинаем алгоритм уменьшения с начала. Плюс: после такого уменьшение все тесты всегда будут валидными с точки зрения грамматики. Минусы: тесты "меньше" уменьшаются по сравнению с АФЛ. Вывод из статьи: таким образом, несмотря на относительно низкий коэффициент обрезки, эта стратегия обрезки с учетом грамматики может значительно улучшить коэффициент валидности для тестовых входных данных после обрезки, что облегчает и ускоряет дальнейшую работу с ними.
Не совсем стандартные мутации АФЛ, а с улучшением под грамматику. Сначала создаётся словарь токенов(интересных слов). Его можно либо забить вручную, либо при помощи АФЛ. Далее делается предположение, что все токены должны состоять из цифр и букв. При мутации новый токен(из словаря) либо вставляется между двумя старыми, либо заменяет один из них.
Берётся текущий тест и случайный из очереди длины <=10000 байт. Они парсятся и из их поддеревеьев формируется множество для мутаций. Берётся не больше 10000 поддеревеьев и длина каждого поддерева ограничена 200 байтами. Затем каждое поддерево текущего теста заменяется на каждое поддерево из множества, формируя новый тест. Плюсы: очень подробный перебор возможных тестов. Минусы: несмотря на ограничения тестов получается очень много.
В статье сравнивали различные мутации. Самыми удачными оказались мутация замены поддеревьев и перезапись токенов при помощи словаря, определённого человеком.